Tag Archives: r script
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, Part One
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, Part One
A Tutorial by D. M. Wiig, Professor of Political Science, Grand View University
In my most recent tutorials I have discussed the use of the tabplot() package to visualize multivariate mixed data types in large datasets. This type of table display is a handy way to identify possible relationships among variables, but is limited in terms of interpretation and the number of variables that can be meaningfully displayed.
Social science research projects often start out with many potential independent predictor variables for a given dependant variable. If these variables are all measured at the interval or ratio level a correlation matrix often serves as a starting point to begin analyzing relationships among variables.
In this tutorial I will use the R packages SemiPar, qgraph and Hmisc in addition to the basic packages loaded when R is started. The code is as follows:
###################################################
#data from package SemiPar; dataset milan.mort
#dataset has 3652 cases and 9 vars
##################################################
install.packages(“SemiPar”)
install.packages(“Hmisc”)
install.packages(“qgraph”)
library(SemiPar)
####################################################
One of the datasets contained in the SemiPar packages is milan.mort. This dataset contains nine variables and data from 3652 consecutive days for the city of Milan, Italy. The nine variables in the dataset are as follows:
rel.humid (relative humidity)
tot.mort (total number of deaths)
resp.mort (total number of respiratory deaths)
SO2 (measure of sulphur dioxide level in ambient air)
TSP (total suspended particles in ambient air)
day.num (number of days since 31st December, 1979)
day.of.week (1=Monday; 2=Tuesday; 3=Wednesday; 4=Thursday; 5=Friday; 6=Saturday; 7=Sunday
holiday (indicator of public holiday: 1=public holiday, 0=otherwise
mean.temp (mean daily temperature in degrees celsius)
To look at the structure of the dataset use the following
#########################################
library(SemiPar)
data(milan.mort)
str(milan.mort)
###############################################
Resulting in the output:
> str(milan.mort)
‘data.frame’: 3652 obs. of 9 variables:
$ day.num : int 1 2 3 4 5 6 7 8 9 10 …
$ day.of.week: int 2 3 4 5 6 7 1 2 3 4 …
$ holiday : int 1 0 0 0 0 0 0 0 0 0 …
$ mean.temp : num 5.6 4.1 4.6 2.9 2.2 0.7 -0.6 -0.5 0.2 1.7 …
$ rel.humid : num 30 26 29.7 32.7 71.3 80.7 82 82.7 79.3 69.3 …
$ tot.mort : num 45 32 37 33 36 45 46 38 29 39 …
$ resp.mort : int 2 5 0 1 1 6 2 4 1 4 …
$ SO2 : num 267 375 276 440 354 …
$ TSP : num 110 153 162 198 235 …
As is seen above, the dataset contains 9 variables all measured at the ratio level and 3652 cases.
In doing exploratory research a correlation matrix is often generated as a first attempt to look at inter-relationships among the variables in the dataset. In this particular case a researcher might be interested in looking at factors that are related to total mortality as well as respiratory mortality rates.
A correlation matrix can be generated using the cor function which is contained in the stats package. There are a variety of functions for various types of correlation analysis. The cor function provides a fast method to calculate Pearson’s r with a large dataset such as the one used in this example.
To generate a zero order Pearson’s correlation matrix use the following:
###############################################
#round the corr output to 2 decimal places
#put output into variable cormatround
#coerce data to matrix
#########################################
library(Hmisc)
cormatround round(cormatround, 2)
#################################################
The output is:
> cormatround > round(cormatround, 2) Day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 1.00 0.00 0.01 0.02 0.12 -0.28 0.22 -0.34 0.07 day.of.week 0.00 1.00 0.00 0.00 0.00 -0.05 0.03 -0.05 -0.05 holiday 0.01 0.00 1.00 -0.07 0.01 0.00 0.01 0.00 -0.01 mean.temp 0.02 0.00 -0.07 1.00 -0.25 -0.43 -0.26 -0.66 -0.44 rel.humid 0.12 0.00 0.01 -0.25 1.00 0.01 -0.03 0.15 0.17 tot.mort -0.28 -0.05 0.00 -0.43 0.01 1.00 0.47 0.44 0.25 resp.mort -0.22 -0.03 -0.01 -0.26 -0.03 0.47 1.00 0.32 0.15 SO2 -0.34 -0.05 0.00 -0.66 0.15 0.44 0.32 1.00 0.63 TSP 0.07 -0.05 -0.01 -0.44 0.17 0.25 0.15 0.63 1.00 |
|
|
The matrix can be examined to look at intercorrelations among the nine variables, but it is very difficult to detect patterns of correlations within the matrix. Also, when using the cor() function raw Pearson’s coefficients are reported, but significance levels are not.
A correlation matrix with significance can be generated by using the rcorr() function, also found in the Hmisc package. The code is:
#############################################
library(Hmisc)
rcorr(as.matrix(milan.mort, type=”pearson”))
###################################################
The output is:
> rcorr(as.matrix(milan.mort, type="pearson")) day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 1.00 0.00 0.01 0.02 0.12 -0.28 -0.22 -0.34 0.07 day.of.week 0.00 1.00 0.00 0.00 0.00 -0.05 -0.03 -0.05 -0.05 holiday 0.01 0.00 1.00 -0.07 0.01 0.00 -0.01 0.00 -0.01 mean.temp 0.02 0.00 -0.07 1.00 -0.25 -0.43 -0.26 -0.66 -0.44 rel.humid 0.12 0.00 0.01 -0.25 1.00 0.01 -0.03 0.15 0.17 tot.mort -0.28 -0.05 0.00 -0.43 0.01 1.00 0.47 0.44 0.25 resp.mort -0.22 -0.03 -0.01 -0.26 -0.03 0.47 1.00 0.32 0.15 SO2 -0.34 -0.05 0.00 -0.66 0.15 0.44 0.32 1.00 0.63 TSP 0.07 -0.05 -0.01 -0.44 0.17 0.25 0.15 0.63 1.00 n= 3652 P day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 0.9771 0.5349 0.2220 0.0000 0.0000 0.0000 0.0000 day.of.week 0.9771 0.7632 0.8727 0.8670 0.0045 0.1175 0.0061 holiday 0.5349 0.7632 0.0000 0.4648 0.8506 0.6115 0.7793 0.4108 mean.temp 0.2220 0.8727 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 rel.humid 0.0000 0.8670 0.4648 0.0000 0.3661 0.1096 0.0000 0.0000 tot.mort 0.0000 0.0045 0.8506 0.0000 0.3661 0.0000 0.0000 0.0000 resp.mort 0.0000 0.1175 0.6115 0.0000 0.1096 0.0000 0.0000 0.0000 SO2 0.0000 0.0024 0.7793 0.0000 0.0000 0.0000 0.0000 0.0000 TSP 0.0000 0.0061 0.4108 0.0000 0.0000 0.0000 0.0000 0.0000 |
|
|
In a future tutorial I will discuss using significance levels and correlation strengths as methods of reducing complexity in very large correlation network structures.
The recently released package qgraph () provides a number of interesting functions that are useful in visualizing complex inter-relationships among a large number of variables. To quote from the CRAN documentation file qraph() “Can be used to visualize data networks as well as provides an interface for visualizing weighted graphical models.” (see CRAN documentation for ‘qgraph” version 1.4.2. See also http://sachaepskamp.com/qgraph).
The qgraph() function has a variety of options that can be used to produce specific types of graphical representations. In this first tutorial segment I will use the milan.mort dataset and the most basic qgraph functions to produce a visual graphic network of intercorrelations among the 9 variables in the dataset.
The code is as follows:
###################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
###################################################
cormat=cor(milan.mort) #correlation matrix generated
###################################################
###################################################
#now plot a graph of the correlation matrix
###################################################
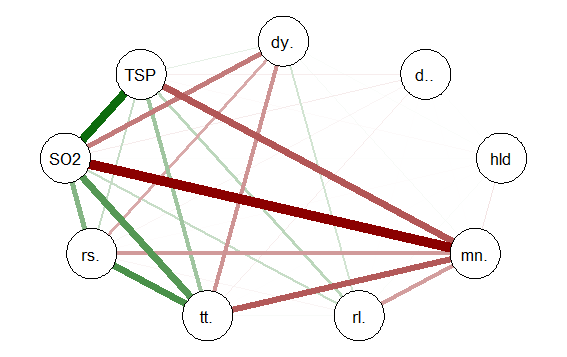
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”groups”, vsize=10)
###################################################
This code produces the following correlation network:
The correlation network provides a very useful visual picture of the intercorrelations as well as positive and negative correlations. The relative thickness and color density of the bands indicates strength of Pearson’s r and the color of each band indicates a positive or negative correlation – red for negative and green for positive.
By changing the “layout=” option from “groups” to “spring” a slightly different perspective can be seen. The code is:
########################################################
#Code to produce alternative correlation network:
#######################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
##############################################################
cormat=cor(milan.mort) #correlation matrix generated
##############################################################
###############################################################
#now plot a circle graph of the correlation matrix
##########################################################
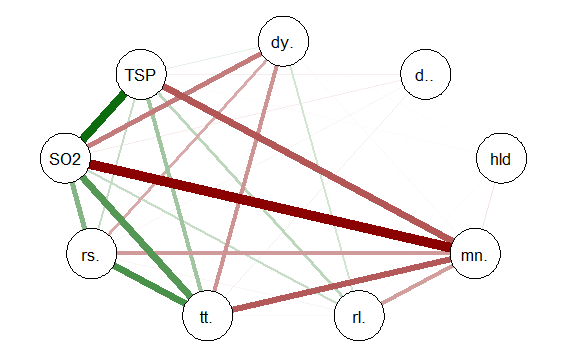
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”spring”, vsize=10)
###############################################################
The graph produced is below:

Once again the intercorrelations, strength of r and positive and negative correlations can be easily identified. There are many more options, types of graph and procedures for analysis that can be accomplished with the qgraph() package. In future tutorials I will discuss some of these.
R For Beginners: Basic Graphics Code to Produce Informative Graphs, Part Two, Working With Big Data
R for beginners: Some basic graphics code to produce informative graphs, part two, working with big data
A tutorial by D. M. Wiig
In part one of this tutorial I discussed the use of R code to produce 3d scatterplots. This is a useful way to produce visual results of multi- variate linear regression models. While visual displays using scatterplots is a useful tool when using most datasets it becomes much more of a challenge when analyzing big data. These types of databases can contain tens of thousands or even millions of cases and hundreds of variables.
Working with these types of data sets involves a number of challenges. If a researcher is interested in using visual presentations such as scatterplots this can be a daunting task. I will start by discussing how scatterplots can be used to provide meaningful visual representation of the relationship between two variables in a simple bivariate model.
To start I will construct a theoretical data set that consists of ten thousand x and y pairs of observations. One method that can be used to accomplish this is to use the R rnorm() function to generate a set of random integers with a specified mean and standard deviation. I will use this function to generate both the x and y variable.
Before starting this tutorial make sure that R is running and that the datasets, LSD, and stats packages have been installed. Use the following code to generate the x and y values such that the mean of x= 10 with a standard deviation of 7, and the mean of y=7 with a standard deviation of 3:
##############################################
## make sure package LSD is loaded
##
library(LSD)
x <- rnorm(50000, mean=10, sd=15) # # generates x values #stores results in variable x
y <- rnorm(50000, mean=7, sd=3) ## generates y values #stores results in variable y
####################################################
Now the scatterplot can be created using the code:
##############################################
## plot randomly generated x and y values
##
plot(x,y, main=”Scatterplot of 50,000 points”)
####################################################
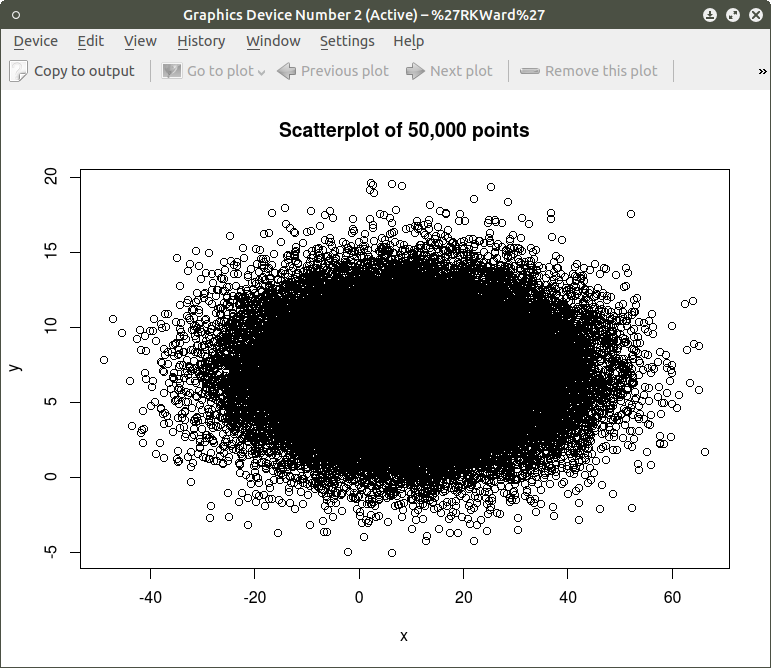
As can be seen the resulting plot is mostly a mass of black with relatively few individual x and y points shown other than the outliers. We can do a quick histogram on the x values and the y values to check the normality of the resulting distribution. This shown in the code below:
####################################################
## show histogram of x and y distribution
####################################################
hist(x) ## histogram for x mean=10; sd=15; n=50,000
##
hist(y) ## histogram for y mean=7; sd=3; n-50,000
####################################################
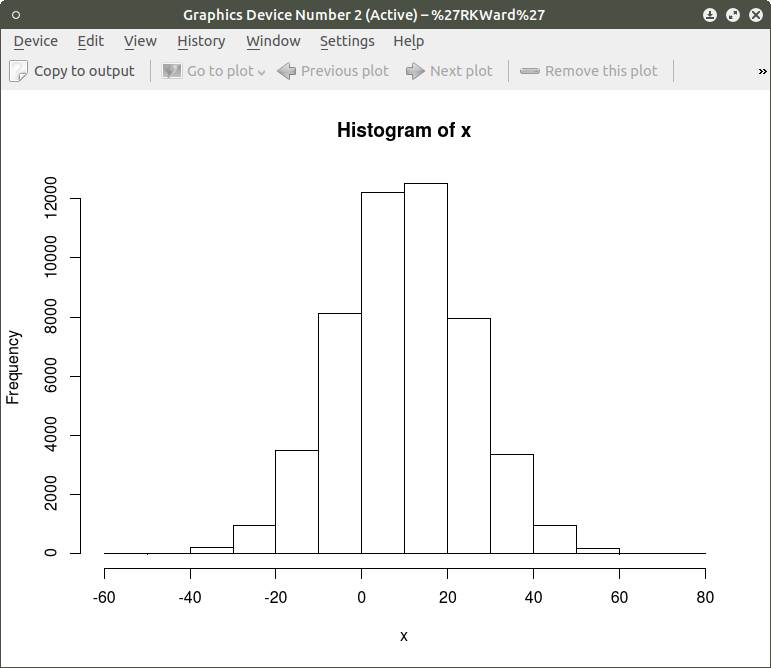
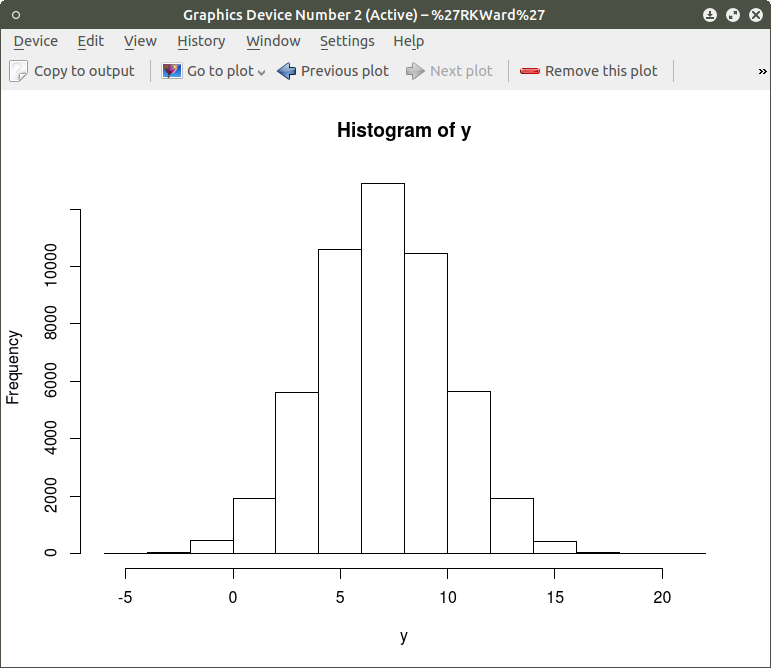
The histogram shows a normal distribution for both variables. As is expected, in the x vs. y scatterplot the center mass of points is located at the x = 10; y=7 coordinate of the graph as this coordinate contains the mean of each distribution. A more meaningful scatterplot of the dataset can be generated using a the R functions smoothScatter() and heatscatter(). The smoothScatter() function is located in the graphics package and the heatscatter() function is located in the LSD package.
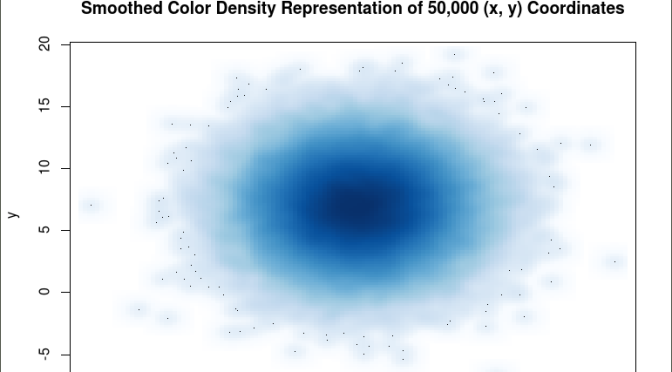
The smoothScatter() function creates a smoothed color density representation of a scatterplot. This allows for a better visual representation of the density of individual values for the x and y pairs. To use the smoothScatter() function with the large dataset created above use the following code:
##############################################
## use smoothScatter function to visualize the scatterplot of #50,000 x ## and y values
## the x and y values should still be in the workspace as #created above with the rnorm() function
##
smoothScatter(x, y, main = “Smoothed Color Density Representation of 50,000 (x,y) Coordinates”)
##
####################################################

The resulting plot shows several bands of density surrounding the coordinates x=10, y=7 which are the means of the two distributions rather than an indistinguishable mass of dark points.
Similar results can be obtained using the heatscatter() function. This function produces a similar visual based on densities that are represented as color bands. As indicated above, the LSD package should be installed and loaded to access the heatscatter() function. The resulting code is:
##############################################
## produce a heatscatter plot of x and y
##
library(LSD)
heatscatter(x,y, main=”Heat Color Density Representation of 50,000 (x, y) Coordinates”) ## function heatscatter() with #n=50,000
####################################################
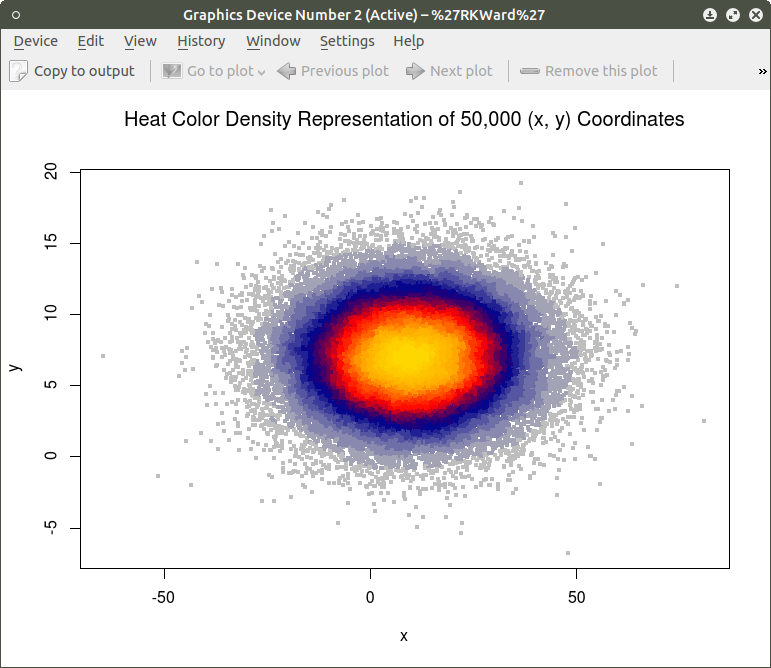
In comparing this plot with the smoothScatter() plot one can more clearly see the distinctive density bands surrounding the coordinates x=10, y=7. You may also notice depending on the computer you are using that there is a noticeably longer processing time required to produce the heatscatter() plot.
This tutorial has hopefully provided some useful information relative to visual displays of large data sets. In the next segment I will discuss how these techniques can be used on a live database containing millions of cases.
R for Beginners: Some Simple Code to Produce Informative Graphs, Part One
A Tutorial by D. M. Wiig
The R programming language has a multitude of packages that can be used to display various types of graph. For a new user looking to display data in a meaningful way graphing functions can look very intimidating. When using a statistics package such as SPSS, Stata, Minitab or even some of the R Gui’s such R Commander sophisticated graphs can be produced but with a limited range of options. When using the R command line to produce graphics output the user has virtually 100 percent control over every aspect of the graphics output.
For new R users there are some basic commands that can be used that are easy to understand and offer a large degree of control over customisation of the graphical output. In part one of this tutorial I will discuss some R scripts that can be used to show typical output from a basic correlation and regression analysis.
For the first example I will use one of the datasets from the R MASS dataset package. The dataset is ‘UScrime´ which contains data on certain factors and their relationship to violent crime. In the first example I will produce a simple scatter plot using the variables ‘GDP’ as the independent variable and ´crimerate´ the dependent variable which is represented by the letter ‘y’ in the dataset.
Before starting on this project install and load the R package ‘MASS.’ Other needed packages are loaded when R is started. The scatter plot is produced using the following code:
####################################################
### make sure that the MASS package is installed
###################################################
library(MASS) ## load MASS
attach(UScrime) ## use the UScrime dataset
## plot the two dimensional scatterplot and add appropriate #labels
#
plot(GDP, y,
main=”Basic Scatterplot of Crime Rate vs. GDP”,
xlab=”GDP”,
ylab=”Crime Rate”)
#
####################################################
The above code produces a two-dimensional plot of GDP vs. Crimerate. A regression line can be added to the graph produced by including the following code:
####################################################
## add a regression line to the scatter plot by using simple bivariate #linear model
## lm generates the coefficients for the regression model.extract
## col sets color; lwd sets line width; lty sets line type
#
abline(lm(y ~ GDP), col=”red”, lwd=2, lty=1)
#
####################################################
As is often the case in behavioral research we want to evaluate models that involve more than two variables. For multivariate models scatter plots can be generated using a 3 dimensional version of the R plot() function. For the above model we can add a third variable ‘Ineq’ from the dataset which is a measure the distribution of wealth in the population. Since we are now working with a multivariate linear model of the form ‘y = b1(x1) + b2(x2) + a’ we can use the R function scatterplot3d() to generate a 3 dimensional representation of the variables.
Once again we use the MASS package and the dataset ‘UScrime’ for the graph data. The code is seen below:
####################################################
## create a 3d graph using the variables y, GDP, and Ineq
####################################################
#
library(scatterplot3d) ##load scatterplot3d function
require(MASS)
attach(UScrime) ## use data from UScrime dataset
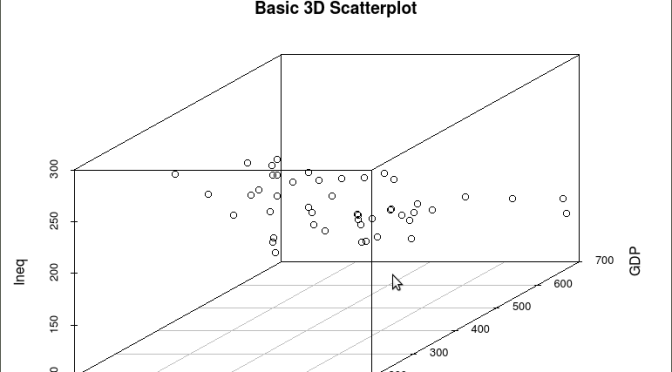
scatterplot3d(y,GDP, Ineq,
main=”Basic 3D Scatterplot”) ## graph 3 variables, y
#
###################################################
The following graph is produced:

The above code will generate a basic 3d plot using default values. We can add straight lines from the plane of the graph to each of the data points by setting the graph type option as ‘type=”h”, as seen in the code below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical lines from plane with this option
main=”3D Scatterplot with Vertical Lines”)
####################################################
This results in the graph:

There are numerous options that can be used to go beyond the basic 3d plot. Refer to CRAN documentation to see these. A final addition to the 3d plot as discussed here is the code needed to generate the regression plane of our linear regression model using the y (crimerate), GDP, and Ineq variables. This is accomplished using the plane3d() option that will draw a plane through the data points of the existing plot. The code to do this is shown below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical line from plane to data points with this #option
main=”3D Scatterplot with Vertical Lines”)
## now calculate and add the linear regression data
model1 <- lm(y ~ GDP + Ineq) #
model$plane3d(model1) ## link the 3d scatterplot in ‘model’ to the ‘plane3d’ option with ‘model1’ regression information
#
####################################################
The resulting graph is:
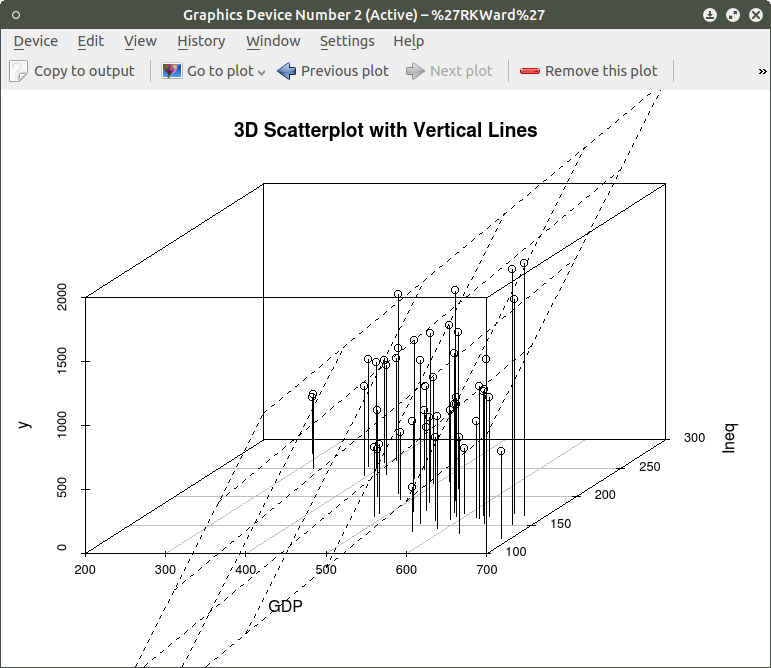
To draw a regression plane through the data points only change the ‘type’ option to ‘type=”p” to show the data points without vertical lines to the plane. There are also many other options that can be used. See the CRAN documentation to review them.
I have hopefully shown that relatively simple R code can be used to generate some informative and useful graphs. Once you start to become aware of how to use the multitude of options for these functions you can have virtually total control of the visual presentation of data. I will discuss some additional simple graphs in the next tutorial that I post.
R For Beginners: Some Simple R Code to do Common Statistical Procedures, Part Two
An R tutorial by D. M. Wiig
This posting contains an embedded Word document. To view the document full screen click on the icon in the lower right hand corner of the embedded document.
R For Beginners: A Video Tutorial on Installing and Using the Deducer Statistics Package
R For Beginners: A Video Tutorial on Installing and Using the Deducer Statistics Package with the R Console
In previous tutorials I have discussed the use of R Commander and Deducer statistical packages that provide a menu based GUI for R. In this video tutorial I will discuss downloading and installing the Deducer statistics package. This video is designed to support my previous tutorial on the same subject.
I have embedded the video below, I hope you find this tutorial a useful adjunct to installing and using the menu based Deducer package.
This document is an embedded Word document. To view it full screen click on the icon in the lower right corner of the screen

R for Beginners: Using R Commander, Graphing and Correlation
A tutorial by Douglas M. Wiig
Please note that this post is an embedded Word document. To read the document full screen click on the icon in the lower right portion of the document window.
R for Beginners: Installing and Using the R Commander GUI, Part One
A tutorial by D.M. Wiig
This tutorial is posted as an embedded Word document. To view the document full screen click on the button in the lower right corner of the window. Please note that you must be online for the full page Word document display to work.
R For Beginners: Installing and Using the R Console in a Windows Environment
An R tutorial by D. M. Wiig
This tutorial is posted as an embedded Word document. To view the document full screen click on the icon in the lower-right corner of the document window.
My next post covering installing and using the Rcommander GUI will be out in a day or two.

Ternary Diagrams Using R: An Example Using Election Outcomes
Ternary Diagrams Using R: An Example Using Election Outcomes
A tutorial by D. M. Wiig
In part one of this tutorial I discussed creating a ternary diagram using a simple data frame that contained five hypothetical cases. In this tutorial I will expand on that foundation by creating a more informative ternary diagram using live data.
A useful application of this package in social science research is creating a visual display of parliamentary election outcomes. Specifically we can use a ternary graph to examine the distribution of seats in the British House of Commons over a period of time. Since the UK uses a proportional system to allocate seats in the House of Commons there can be a variety of outcomes in any given national election.
Since 1945 general elections in the UK have produced a division of seats among the Labour, Conservative, and various minor parties. To demonstrate how this division of seats can be shown over time data was collected for all of the general elections from the years 1945 to 2015. These data show the percentage of the popular vote won by each party and the number of seats allocated to that party based on the vote division(retrieved from http://www.ukpolitical.info). I have created a summary table of these results as follows:
Year Con Lab LD+Other SeatsCon SeatsLab SeatsOther
2015 36.9 30.4 32.7 331 232 95
2010 36.1 29 34.9 306 258 85
2005 35.2 32.4 32.4 355 198 92
2001 40.7 31.7 27.6 412 166 81
1997 43.2 30.7 26.1 418 165 76
1992 42.3 35.2 23.5 336 271 44
1987 42.2 30.8 27 375 229 48
1983 42.4 27.6 26.9 397 209 27
1979 43.9 36.9 15.8 339 268 28
1974 39.2 35.8 21.8 319 276 39
1974 37.1 37.9 20.1 301 296 38
1970 46.4 43 8.6 330 287 19
1966 47.9 41.9 8.5 363 253 25
1964 44.1 53.4 11.2 317 304 22
1959 49.4 43.8 5.9 365 258 19
1955 49.7 46.4 0 344 277 18
1951 48 48.8 2.5 321 295 18
1950 46.1 43.5 9.1 315 297 22
1945 47.8 39.8 1 393 213 57
The UK has a two party dominant system with a number of minor parties that regularly contest elections. As indicated above, a proportional representation method of allocating seats is used so these minor parties are able to gain some representation in the Commons. For readers interested in learning more about political parties in the UK there are a number of resources readily available at various online and other sources.
For purposes of this example I have added the popular vote of all minor parties together in the ‘LD+Other’ column, and the number of seats gained in the ‘SeatsOther’ column. By plotting the three variables ‘SeatsCon’, ‘SeatsLab’, and ‘SeatsOther’ by year on a ternary diagram we can visualize any changes in the mixture of seats won for the three groups. Before working through this tutorial make sure that you have the ggplot, ggplot2, and ggtern packages loaded into your R environment.
I originally created the table shown above using Excel and then imported it into R studio for analysis. If you are not using R studio you can enter the data via the R data editor as shown in the previous tutorial, or put the data into an Excel or LibreOffice spreadsheet and import it into R using the read.spss() function that I have discussed in earlier tutorials. You can also use any other method that you are familiar with to get the data into your R environment.
Once the data set is loaded use the following code to create the ternary diagram. Note that in this diagram we are using the base code as shown in the first tutorial with some additions that make the diagram easier to interpret such as the vector arrows and legend. The code segment is:
################################################### #create ternary plot using seats allocated by party for each election #uses enhanced formatting for easier interpretation #results of #ggtern function are placed in ‘plot for rendering ################################################### plot <- ggtern(data = ukvotedata, aes(x = SeatsCon, y = SeatsLab, z = SeatsOther)) +geom_point(aes(fill = Year), size = 4, shape = 21, color = “black”) + ggtitle(“Proportion of Seats Won 1945-2015”) + labs(fill = “Year”) + theme_rgbw() + theme(legend.position = c(0,1), legend.justification = c(0, 1)) ###################################################
To show the diagram simply use:
################################################### #now plot the diagram ################################################### plot ###################################################
The resulting ternary diagram is:

Each point on the graph represent the relative division of seats for each of the 19 elections in the table. The shading represents the year with the darkest being 1945 and the lightest 2015. The diagram clearly shows the trend toward more minor party representation and a move away from the two major parties over time. Indeed coalition governments resulted in several of the more recent elections due to the increase in minor party influence.
My purpose here is not to discuss UK politics but to show how ternary diagrams can be used in a social science application. With the many additions and extensions that are being added to the ggtern package it can be a very power device for graphical analysis.
