Visual Representation of Text Data Sets Using the R tm and wordcloud Packages: Part One
Douglas M. Wiig
This paper is the next installment in series that examines the use of R scripts to present and analyze complex data sets using various types of visual representations. Previous papers have discussed data sets containing a small number of cases and many variable, and data sets with a large number of cases and many variables. The previous tutorials have focused on data sets that were numeric. In this tutorial I will discuss some uses of the R packages tm and wordcloud to meaningfully display and analyze data sets that are composed of text. These types of data sets include formal addresses, speeches, web site content, Twitter posts, and many other forms of text based communication.
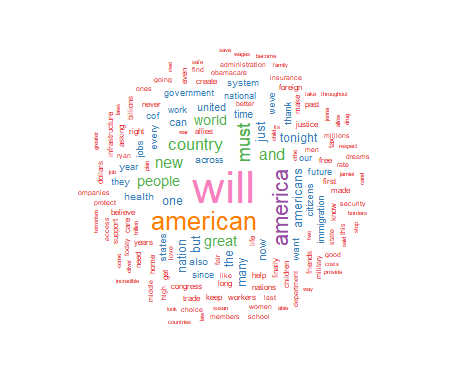
I will present basic R script to process a text file and display the frequency of significant words contained in the text. The results include a visual display of the words using the size of the font to indicate the relative frequency of the word. This approach displays increasing font size as specific word frequency increases. This type of visualization of data is generally referred to as a "wordcloud." To illustrate the use of this approach I will produce a wordcloud that contains the text from the 2017 Presidental State of the Union Address.
There are generally four steps involved in creating a wordcloud. The first step involves loading the selected text file and required packages into the R environment. In the second step the text file is converted into a corpus file type and is cleaned of unwanted text, punctuation and other non-text characters. The third step involves processing the cleaned file to determine word frequencies, and in the fourth step the wordcloud graphic is created and displayed.
Installing Required Packages
As discussed in previous tutorials I would highly recommend the use of an IDE such as RStudio when composing R scripts. While it is possible to use the basic editor and package loader that is part of the R distribution, an IDE will give you a wealth of tools for entering, editing, running, and debugging script. While using RStudio to its fullest potential has a fairly steep learning curve, it is relatively easy to successfully navigate and produce less complex R projects such as this one.
Before moving to the specific code for this project run a list of all of the packages that are loaded when R is started. If you are using RStudio click on the "Packages" tab in the lower right quadrant of the screen and look through the list of packages. If you are using the basic R script editor and package loader, at the command prompt use the following command:
#####################################################################################
>installed.packages()
#####################################################################################
The command produces a list of all currently installed packages. Depending on the specific R version that you are using the packages for this project may or may not be loaded and available. I will assume that they will need to be installed. The packages to be loaded are tm, wordcloud, tidyverse, readr, and RColorBrewer. Use the following code:
#############################################################################
#Load required packages
#############################################################################
install.packages("tm") #processes data
install.packages("wordcloud") #creates visual plot
install.packages("tidyverse") #graphics utilities
install.packages("readr") #to load text files
install.packages("RColorBrewer") #for color graphics
#############################################################################
Once the packages are installed the raw text file can be loaded. The complete text of Presidential State of the Union Addresses can be readily accessed on the government web site https://www.govinfo.gov/features/state-of-the-union. The site has sets of complete text for various years that can be downloaded in several formats. For this project I used the 2017 State of the Union downloaded in text format. To load and view the raw text file in the R environment use the "Import Dataset" tab in the upper right quadrant of RStudio or the code below:
#############################################################################
library(readr)
yourdatasetname <- read_table2("path to your data file", col_names = FALSE)
View(dataset)
#############################################################################
Processing The Data
The goal of this step is to produce the word frequencies that will be used by wordcloud to create the wordcloud graphic display. This process entails converting the raw text file into a corpus format, cleaning the file of unwanted text, converting the cleaned file to a text matrix format, and producing the word frequency counts to be graphed. The code below accomplishes these tasks. Follow the comments for a description of each step involved.
###########################################################################
#Take raw text file statu17 and convert to corpus format named docs17
###########################################################################
library(tm)
docs17 <- Corpus(VectorSource(statu17))
###########################################################################
###########################################################################
#Clean punctuation, stopwords, white space
#Three passes create corpus vector source from original file
#A corpus is a collection of text
###########################################################################
library(tm)
library(wordcloud)
data(docs17)
docs17 <- tm_map(docs17,removePunctuation) #remove punctuation
docs17 <- tm_map(docs17,removeWords,stopwords("english")) #remove stopwords
docs17 <- tm_map(docs17,stripWhitespace) #remove white space
###########################################################################
#Cleaned corpus is now formatted into text document matrix
#Then frequency count done for each word in matrix
#dmat <-create matrix; dval <-sort; dframe <-count word frequencies
#docmat <- converts cleaned corpus to text matrix for processing
###########################################################################
docmat <- TermDocumentMatrix(docs17)
dmat <- as.matrix(docmat)
dval <- sort(rowSums(dmat),decreasing=TRUE)
dframe <- data.frame(word=names(dval),freq=dval)
###########################################################################
Once these steps have been completed the data frame "dframe" will now be used by the wordcloud package to produce the graphic.
Producing the Wordcloud Graphic
We are now ready to produce the graphic plot of word frequencies. The resulting display can be manipulated using a number of settings including color schemes, number of words displayed, size of the wordcloud, minimum word frequency of words to display, and many other factors. Refer to Appendix B for additional information.
For this project I have chosen to use a white background and a multi-colored word display. The display is medium size, with 150 words maximum, and a minimum word frequency of two. The resulting graphic is shown in Figure 1. Use the code below to produce and display the wordcloud:
##########################################################################################
#Final step is to use wordcloud to generate graphics
#There are a number of options that can be set
#See Appendix for details
#Use RColorBrewer to generate a color wordcloud
#RColorBrewer has many options, see Appendix for details
##########################################################################################
library(RColorBrewer)
set.seed(1234) #use if random.color=TRUE
par(bg="white") #background color
wordcloud(dframe$word,dframe$freq,colors=brewer.pal(8,"Set1"),random.order=FALSE,
scale=c(2.75,0.20),min.freq=2,max.words=150,rot.per=0.35)
##########################################################################################
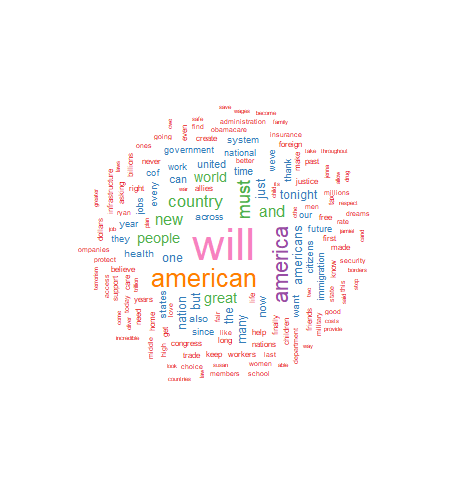 As seen above, the wordcloud display is arranged in a manner with the most frequently used words in the largest font at the center of the graph. As word frequency drops there are somewhat concentric rings of words in smaller and smaller fonts with the smallest font outer rings set by the wordcloud parameter min.freq=2. At this point I will leave an analysis of the wordcloud to the interpretation of the reader.
In part two of this tutorial I will discuss further use of the wordcloud package to produce comparison wordclouds using SOTU text files from 2017, 2018, 2019, and 2020. I will also introduce part three of the tutorial which will discuss using wordcloud with very large text data sets such as Twitter posts.
Appendix A: Resources and References
This section contains links and references to resources used in this project. For further information on specific R packages see the links below.
Package tm:
https://cran.r-project.org/web/packages/tm/tm.pdf
Package RColorBrewer:
https://cran.r-project.org/web/packages/RColorBrewer/RColorBrewer.pdf
Package readr:
https://cran.r-project.org/web/packages/readr/readr.pdf
Package wordcloud:
https://cran.r-project.org/web/packages/wordcloud/wordcloud.pdf
Package tidyverse
https://cran.r-project.org/web/packages/tidyverse/tidyverse.pdf
To download the RStudio IDE:
https://www.rstudio.com/products/rstudio/download
General works relating to R programming:
Robert Kabacoff, R in Action: Data Analysis and Graphics With R, Sheleter Island, NY: Manning Publications, 2011.
N.D. Lewis, Visualizing Complex Data in R, N.D. Lewis, 2013.
The text data for the 2017 State of the Union Address was downloaded from:
https://www.govinfo.gov/features/state-of-the-union
Appendix B: R Functions Syntax Usage
This appendix contains the syntax usage for the main R functions used in this paper. See the links in Appendix A for more detail on each function.
readr:
read_table2(file,col_names = TRUE,col_types = NULL,locale = default_locale(),na = "NA",
skip = 0,n_max = Inf,guess_max = min(n_max, 1000),progress = show_progress(),comment = "",
skip_empty_rows = TRUE)
wordcloud:
wordcloud(words,freq,scale=c(4,.5),min.freq=3,max.words=Inf,
random.order=TRUE, random.color=FALSE, rot.per=.1,
colors="black",ordered.colors=FALSE,use.r.layout=FALSE,
fixed.asp=TRUE, ...)
rcolorbrewer:
brewer.pal(n, name)
display.brewer.pal(n, name)
display.brewer.all(n=NULL, type="all", select=NULL, exact.n=TRUE,colorblindFriendly=FALSE)
brewer.pal.info
tm:
tm_map(x, FUN, ...)
All R programming for this project was done using RStudio Version 1.2.5033
The PDF version of this document was produced using TeXstudio 2.12.6
Author: Douglas M. Wiig 4/01/2021
Web Site: http://dmwiig.net
Click the links below to open the PDF version of this post.
As seen above, the wordcloud display is arranged in a manner with the most frequently used words in the largest font at the center of the graph. As word frequency drops there are somewhat concentric rings of words in smaller and smaller fonts with the smallest font outer rings set by the wordcloud parameter min.freq=2. At this point I will leave an analysis of the wordcloud to the interpretation of the reader.
In part two of this tutorial I will discuss further use of the wordcloud package to produce comparison wordclouds using SOTU text files from 2017, 2018, 2019, and 2020. I will also introduce part three of the tutorial which will discuss using wordcloud with very large text data sets such as Twitter posts.
Appendix A: Resources and References
This section contains links and references to resources used in this project. For further information on specific R packages see the links below.
Package tm:
https://cran.r-project.org/web/packages/tm/tm.pdf
Package RColorBrewer:
https://cran.r-project.org/web/packages/RColorBrewer/RColorBrewer.pdf
Package readr:
https://cran.r-project.org/web/packages/readr/readr.pdf
Package wordcloud:
https://cran.r-project.org/web/packages/wordcloud/wordcloud.pdf
Package tidyverse
https://cran.r-project.org/web/packages/tidyverse/tidyverse.pdf
To download the RStudio IDE:
https://www.rstudio.com/products/rstudio/download
General works relating to R programming:
Robert Kabacoff, R in Action: Data Analysis and Graphics With R, Sheleter Island, NY: Manning Publications, 2011.
N.D. Lewis, Visualizing Complex Data in R, N.D. Lewis, 2013.
The text data for the 2017 State of the Union Address was downloaded from:
https://www.govinfo.gov/features/state-of-the-union
Appendix B: R Functions Syntax Usage
This appendix contains the syntax usage for the main R functions used in this paper. See the links in Appendix A for more detail on each function.
readr:
read_table2(file,col_names = TRUE,col_types = NULL,locale = default_locale(),na = "NA",
skip = 0,n_max = Inf,guess_max = min(n_max, 1000),progress = show_progress(),comment = "",
skip_empty_rows = TRUE)
wordcloud:
wordcloud(words,freq,scale=c(4,.5),min.freq=3,max.words=Inf,
random.order=TRUE, random.color=FALSE, rot.per=.1,
colors="black",ordered.colors=FALSE,use.r.layout=FALSE,
fixed.asp=TRUE, ...)
rcolorbrewer:
brewer.pal(n, name)
display.brewer.pal(n, name)
display.brewer.all(n=NULL, type="all", select=NULL, exact.n=TRUE,colorblindFriendly=FALSE)
brewer.pal.info
tm:
tm_map(x, FUN, ...)
All R programming for this project was done using RStudio Version 1.2.5033
The PDF version of this document was produced using TeXstudio 2.12.6
Author: Douglas M. Wiig 4/01/2021
Web Site: http://dmwiig.net
Click the links below to open the PDF version of this post.
Tag Archives: r code
An R Tutorial: Visual Representation of Complex Multivariate Relationships Using the R ‘qgraph’ Package, Part Two
An R programming tutorial by D.M. Wiig
This post is contained in a .pdf document. To access the document click on the green link shown below.
R Tutorial: Visualizing Multivariate Relationships in Large Datasets
R Tutorial: Visualizing multivariate relationships in Large Datasets
A tutorial by D.M. Wiig
In two previous blog posts I discussed some techniques for visualizing relationships involving two or three variables and a large number of cases. In this tutorial I will extend that discussion to show some techniques that can be used on large datasets and complex multivariate relationships involving three or more variables.
In this tutorial I will use the R package nmle which contains the dataset MathAchieve. Use the code below to install the package and load it into the R environment:
####################################################
#code for visual large dataset MathAchieve
#first show 3d scatterplot; then show tableplot variations
####################################################
install.packages(“nmle”) #install nmle package
library(nlme) #load the package into the R environment
####################################################
Once the package is installed take a look at the structure of the data set by using:
####################################################
attach(MathAchieve) #take a look at the structure of the dataset
str(MathAchieve)
####################################################
Classes ‘nfnGroupedData’, ‘nfGroupedData’, ‘groupedData’ and ‘data.frame’: 7185 obs. of 6 variables:
$ School : Ord.factor w/ 160 levels “8367”<“8854″<..: 59 59 59 59 59 59 59 59 59 59 …
$ Minority: Factor w/ 2 levels “No”,”Yes”: 1 1 1 1 1 1 1 1 1 1 …
$ Sex : Factor w/ 2 levels “Male”,”Female”: 2 2 1 1 1 1 2 1 2 1 …
$ SES : num -1.528 -0.588 -0.528 -0.668 -0.158 …
$ MathAch : num 5.88 19.71 20.35 8.78 17.9 …
$ MEANSES : num -0.428 -0.428 -0.428 -0.428 -0.428 -0.428 -0.428 -0.428 -0.428 -0.428 …
– attr(*, “formula”)=Class ‘formula’ language MathAch ~ SES | School
.. ..- attr(*, “.Environment”)=<environment: R_GlobalEnv>
– attr(*, “labels”)=List of 2
..$ y: chr “Mathematics Achievement score”
..$ x: chr “Socio-economic score”
– attr(*, “FUN”)=function (x)
..- attr(*, “source”)= chr “function (x) max(x, na.rm = TRUE)”
– attr(*, “order.groups”)= logi TRUE
>
As can be seen from the output shown above the MathAchieve dataset consists of 7185 observations and six variables. Three of these variables are numeric and three are factors. This presents some difficulties when visualizing the data. With over 7000 cases a two-dimensional scatterplot showing bivariate correlations among the three numeric variables is of limited utility.
We can use a 3D scatterplot and a linear regression model to more clearly visualize and examine relationships among the three numeric variables. The variable SES is a vector measuring socio-economic status, MathAch is a numeric vector measuring mathematics achievment scores, and MEANSES is a vector measuring the mean SES for the school attended by each student in the sample.
We can look at the correlation matrix of these 3 variables to get a sense of the relationships among the variables:
> ####################################################
> #do a correlation matrix with the 3 numeric vars;
> ###################################################
> data(“MathAchieve”)
> cor(as.matrix(MathAchieve[c(4,5,6)]), method=”pearson”)
SES MathAch MEANSES
SES 1.0000000 0.3607556 0.5306221
MathAch 0.3607556 1.0000000 0.3437221
MEANSES 0.5306221 0.3437221 1.0000000
>
In using the cor() function as seen above we can determine the variables used by specifying the column that each numeric variable is in as shown in the output from the str() function. The 3 numeric variables, for example, are in columns 4, 5, and 6 of the matrix.
As discussed in previous tutorials we can visualize the relationship among these three variable by using a 3D scatterplot. Use the code as seen below:
####################################################
#install.packages(“nlme”)
install.packages(“scatterplot3d”)
library(scatterplot3d)
library(nlme) #load nmle package
attach(MathAchieve) #MathAchive dataset is in environment
scatterplot3d(SES, MEANSES, MathAch, main=”Basic 3D Scatterplot”) #do the plot with default options
####################################################
The resulting plot is:
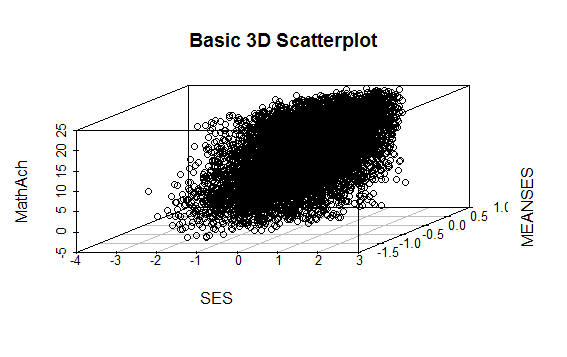
Even though the scatter plot lacks detail due to the large sample size it is still possible to see the moderate correlations shown in the correlation matrix by noting the shape and direction of the data points . A regression plane can be calculated and added to the plot using the following code:
scatterplot3d(SES, MEANSES, MathAch, main=”Basic 3D Scatterplot”) #do the plot with default options
####################################################
##use a linear regression model to plot a regression plane
#y=MathAchieve, SES, MEANSES are predictor variables
####################################################
model1=lm(MathAch ~ SES + MEANSES) ## generate a regression
#take a look at the regression output
summary(model1)
#run scatterplot again putting results in model
model <- scatterplot3d(SES, MEANSES, MathAch, main=”Basic 3D Scatterplot”) #do the plot with default options
#link the scatterplot and linear model using the plane3d function
model$plane3d(model1) ## link the 3d scatterplot in ‘model’ to the ‘plane3d’ option with ‘model1’ regression information
####################################################
The resulting output is seen below:
Call:
lm(formula = MathAch ~ SES + MEANSES)
Residuals:
Min 1Q Median 3Q Max
-20.4242 -4.6365 0.1403 4.8534 17.0496
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.72590 0.07429 171.31 <2e-16 ***
SES 2.19115 0.11244 19.49 <2e-16 ***
MEANSES 3.52571 0.21190 16.64 <2e-16 ***
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.296 on 7182 degrees of freedom
Multiple R-squared: 0.1624, Adjusted R-squared: 0.1622
F-statistic: 696.4 on 2 and 7182 DF, p-value: < 2.2e-16
and the plot with the plane is:

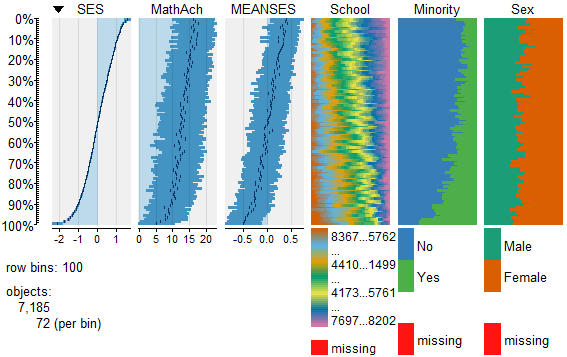
While the above analysis gives us useful information, it is limited by the mixture of numeric values and factors. A more detailed visual analysis that will allow the display and comparison of all six of the variables is possible by using the functions available in the R package Tableplots. This package was created to aid in the visualization and inspection of large datasets with multiple variables.
The MathAchieve contains a total of six variables and 7185 cases. The Tableplots package can be used with datasets larger than 10,000 observations and up to 12 or so variables. It can be used visualize relationships among variables using the same measurement scale or mixed measurement types.
To look at a comparisons of each data type and then view all 6 together begin with the following:
####################################################
attach(MathAchieve) #attach the dataset
#set up 3 data frames with numeric, factors, and mixed
####################################################
mathmix <- data.frame(SES,MathAch,MEANSES,School=factor(School),Minority=factor(Minority),Sex=factor(Sex)) #all 6 vars
mathfact <- data.frame(School=factor(School),Minority=factor(Minority),Sex=factor(Sex)) #3 factor vars
mathnum <- data.frame(SES,MathAch,MEANSES) #3 numeric vars
####################################################
To view a comparison of the 3 numeric variables use:
####################################################
require(tabplot) #load tabplot package
tableplot(mathnum) #generate a table plot with numeric vars only
####################################################
resulting in the following output:

To view only the 3 factor variables use:
####################################################
require(tabplot) #load tabplot package
tableplot(mathfact) #generate a table plot with factors only
####################################################
Resulting in:
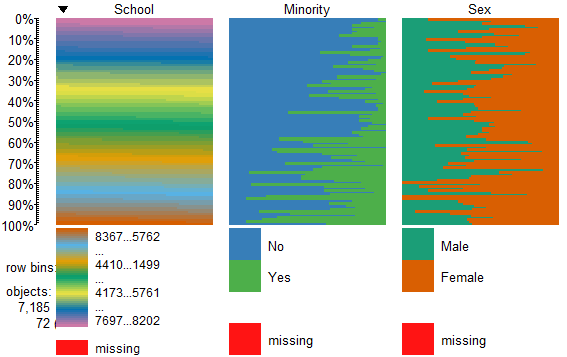
To view and compare table plots of all six variables use:
####################################################
require(tabplot) #load tabplot package
tableplot(mathmix) #generate a table plot with all six variables
####################################################
Resulting in:

Using tableplots is useful in visualizing relationships among a set of variabes. The fact that comparisons can be made using mixed levels of measurement and very large sample sizes provides a tool that the researcher can use for initial exploratory data analysis.
The above visual table comparisons agree with the moderate correlation among the three numeric variables found in the correlation and regression models discussed above. It is also possible to add some additional interpretation by viewing and comparing the mix of both factor and numeric variables.
In this tutorial I have provided a very basic introduction to the use of table plots in visualizing data. Interested readers can find an abundance of information about Tableplot options and interpretations in the CRAN documentation.
In my next tutorial I will continue a discussion of methods to visualize large and complex datasets by looking at some techniques that allow exploration of very large datasets and up to 12 variables or more.
R for Beginners: Some Simple Code to Produce Informative Graphs, Part One
A Tutorial by D. M. Wiig
The R programming language has a multitude of packages that can be used to display various types of graph. For a new user looking to display data in a meaningful way graphing functions can look very intimidating. When using a statistics package such as SPSS, Stata, Minitab or even some of the R Gui’s such R Commander sophisticated graphs can be produced but with a limited range of options. When using the R command line to produce graphics output the user has virtually 100 percent control over every aspect of the graphics output.
For new R users there are some basic commands that can be used that are easy to understand and offer a large degree of control over customisation of the graphical output. In part one of this tutorial I will discuss some R scripts that can be used to show typical output from a basic correlation and regression analysis.
For the first example I will use one of the datasets from the R MASS dataset package. The dataset is ‘UScrime´ which contains data on certain factors and their relationship to violent crime. In the first example I will produce a simple scatter plot using the variables ‘GDP’ as the independent variable and ´crimerate´ the dependent variable which is represented by the letter ‘y’ in the dataset.
Before starting on this project install and load the R package ‘MASS.’ Other needed packages are loaded when R is started. The scatter plot is produced using the following code:
####################################################
### make sure that the MASS package is installed
###################################################
library(MASS) ## load MASS
attach(UScrime) ## use the UScrime dataset
## plot the two dimensional scatterplot and add appropriate #labels
#
plot(GDP, y,
main=”Basic Scatterplot of Crime Rate vs. GDP”,
xlab=”GDP”,
ylab=”Crime Rate”)
#
####################################################
The above code produces a two-dimensional plot of GDP vs. Crimerate. A regression line can be added to the graph produced by including the following code:
####################################################
## add a regression line to the scatter plot by using simple bivariate #linear model
## lm generates the coefficients for the regression model.extract
## col sets color; lwd sets line width; lty sets line type
#
abline(lm(y ~ GDP), col=”red”, lwd=2, lty=1)
#
####################################################
As is often the case in behavioral research we want to evaluate models that involve more than two variables. For multivariate models scatter plots can be generated using a 3 dimensional version of the R plot() function. For the above model we can add a third variable ‘Ineq’ from the dataset which is a measure the distribution of wealth in the population. Since we are now working with a multivariate linear model of the form ‘y = b1(x1) + b2(x2) + a’ we can use the R function scatterplot3d() to generate a 3 dimensional representation of the variables.
Once again we use the MASS package and the dataset ‘UScrime’ for the graph data. The code is seen below:
####################################################
## create a 3d graph using the variables y, GDP, and Ineq
####################################################
#
library(scatterplot3d) ##load scatterplot3d function
require(MASS)
attach(UScrime) ## use data from UScrime dataset
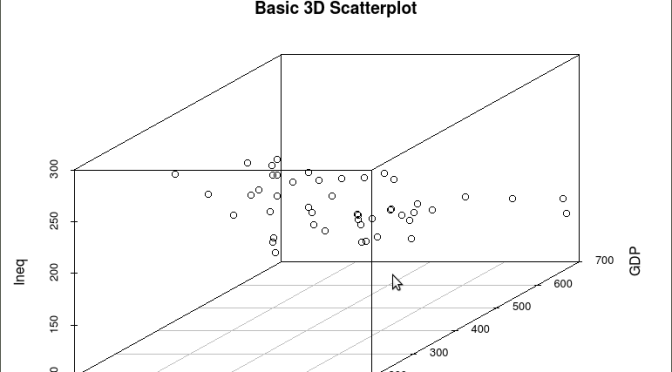
scatterplot3d(y,GDP, Ineq,
main=”Basic 3D Scatterplot”) ## graph 3 variables, y
#
###################################################
The following graph is produced:

The above code will generate a basic 3d plot using default values. We can add straight lines from the plane of the graph to each of the data points by setting the graph type option as ‘type=”h”, as seen in the code below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
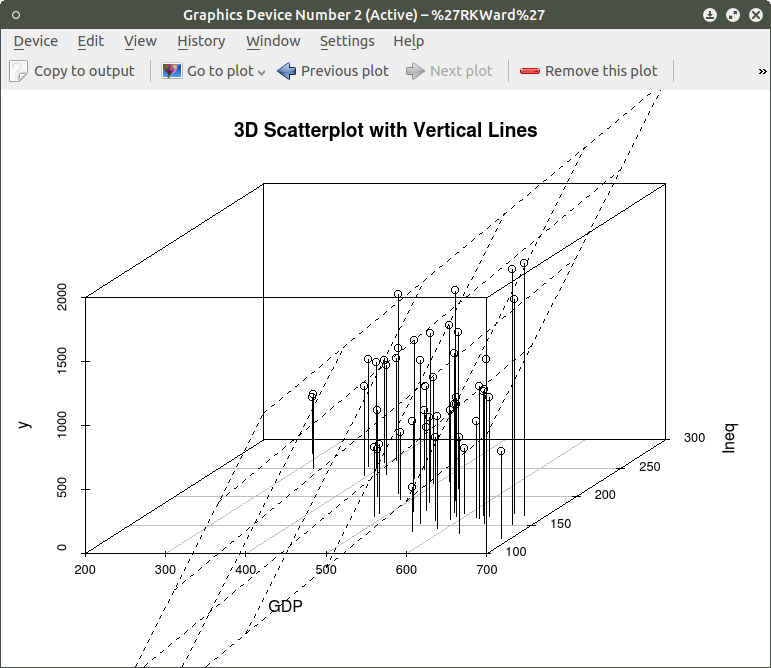
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical lines from plane with this option
main=”3D Scatterplot with Vertical Lines”)
####################################################
This results in the graph:

There are numerous options that can be used to go beyond the basic 3d plot. Refer to CRAN documentation to see these. A final addition to the 3d plot as discussed here is the code needed to generate the regression plane of our linear regression model using the y (crimerate), GDP, and Ineq variables. This is accomplished using the plane3d() option that will draw a plane through the data points of the existing plot. The code to do this is shown below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical line from plane to data points with this #option
main=”3D Scatterplot with Vertical Lines”)
## now calculate and add the linear regression data
model1 <- lm(y ~ GDP + Ineq) #
model$plane3d(model1) ## link the 3d scatterplot in ‘model’ to the ‘plane3d’ option with ‘model1’ regression information
#
####################################################
The resulting graph is:
To draw a regression plane through the data points only change the ‘type’ option to ‘type=”p” to show the data points without vertical lines to the plane. There are also many other options that can be used. See the CRAN documentation to review them.
I have hopefully shown that relatively simple R code can be used to generate some informative and useful graphs. Once you start to become aware of how to use the multitude of options for these functions you can have virtually total control of the visual presentation of data. I will discuss some additional simple graphs in the next tutorial that I post.
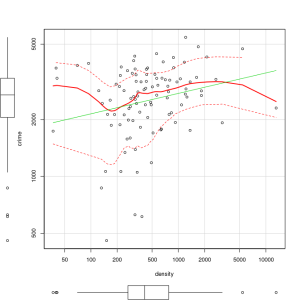
R For Beginners: Some Simple R Code to do Common Statistical Procedures, Part Two
An R tutorial by D. M. Wiig
This posting contains an embedded Word document. To view the document full screen click on the icon in the lower right hand corner of the embedded document.
R For Beginners: Basic R Code for Common Statistical Procedures Part I
An R tutorial by D. M. Wiig
This section gives examples of code to perform some of the most common elementary statistical procedures. All code segments assume that the package ‘car’ has been loaded and the file ‘Freedman’ has been loaded as the active dataset. Use the menu from the R console to load the ’car’ dataset or use the following command line to access the CRAN site list and packages:
install.packages()
Once the ’car’ package has been downloaded and installed use the following command to make it the active library.
require(car)
Load the ‘Freedman’ data file from the dataset ‘car’
data(Freedman, package="car")
List basic descriptives of the variables:
summary(Freedman)
Perform a correlation between two variables using Pearson, Kendall or Spearman’s correlation:
cor(filename[,c("var1","var2")], use="complete.obs", method="pearson")
cor(filename[,c("var1","var2")], use="complete.obs", method="spearman")
cor(filename[,c("var1","var2")], use="complete.obs", method="kendall")
Example:
cor(Freedman[,c("crime","density")], use="complete.obs", method="pearson")
cor(Freedman[,c("crime","density")], use="complete.obs", method="kendall")
cor(Freedman[,c("crime","density")], use="complete.obs", method="spearman")
In the next post I will discuss basic code to produce multiple correlations and linear regression analysis. See other tutorials on this blog for more R code examples for basic statistical analysis.
R Video Tutorial: Basic R Code to Load a Data File and Produce a Histogram
R For Beginners: Some Simple R Code to Load a Data File and Produce a Histogram
A tutorial by D. M. Wiig
I have found that a good method for learning how to write R code is to examine complete code segments written to perform specific tasks and to modify these procedures to fit your specific needs. Trying to master R code in the abstract by reading a book or manual can be informative but is more often confusing. Observing what various code segments do by observing the results allows you to learn with hands-on additions and modifications as needed for your purposes.
In this document I have included a short video tutorial that discusses loading a dataset from the R library, examining the contents of the dataset and selecting one of the variables to examine using a basic histogram. I have included an annotated code chunk of the procedures discussed in the video.
The video appears below with the code segment following.
Here is the annotated code used in the video:
###################################
#use the dataset mtcars from the ‘datasets’ package
#select the variable mpg to do a histogram
#show a frequency distribution of the scores
##########################################
#library is ‘datasets’
#########################################
library(“datasets”)
#########################################
#take a look at what is in ‘datasets’
#########################################
library(help=”datasets”)
#######################################
#take a look at the ‘mtcars’ data
#########################################
View(mtcars)
#######################################
#now do a basic histogram with the hist function
###########################################
hist(mtcars$mpg)
#############################################
#dress up the graph; not covered in the video but easy to do
############################################
hist(mtcars$mpg, col=”red”, xlab = “Miles per Gallon”, main = “Basic Histogram Using ‘mtcars’ Data”)
###################################################
R For Beginners: A Video Tutorial on Installing and Using the Deducer Statistics Package
R For Beginners: A Video Tutorial on Installing and Using the Deducer Statistics Package with the R Console
In previous tutorials I have discussed the use of R Commander and Deducer statistical packages that provide a menu based GUI for R. In this video tutorial I will discuss downloading and installing the Deducer statistics package. This video is designed to support my previous tutorial on the same subject.
I have embedded the video below, I hope you find this tutorial a useful adjunct to installing and using the menu based Deducer package.
This document is an embedded Word document. To view it full screen click on the icon in the lower right corner of the screen
R For Beginners: Installing the JGR GUI On a Linux Platform
A Tutorial by D. M. Wiig
This is an embedded Word document. To view it full screen click on the icon in the lower right cornet of the document.
Watch for more tutorials discussing R statistics on a Linux platform.
R For Beginners: Installing the latest version of R on a Linux platform
R for Beginners: Installing the latest version of R on a Linux platform
A tutorial by D. M. Wiig
One of the nice characteristics of open source software such as R is the rapid development of new releases and updates. While the base core remains stable for a period of time there is a considerable amount of updating, adding, and removing the component packages. At the time of this writing the latest iteration is R version 3.3.1, “Bug in Your Hair.” If you are using a Windows platform you will likely go directly to the archive web site and download the latest distribution as a Windows executable installation package.
If you are using a Linux distribution such as Ubuntu or Debian, the process of adding software is usually accomplished via the menu based installer. These software installers allow R and its dependencies to be downloaded from the community archive.
One of the disadvantages of using this approach is that the versions of some software in the archives may not be updated to the latest version. This is often the case with R.
To insure that you are downloading the latest R version you need to use the platform’s command line to install what is needed. Regradless of which Linux distribution you are using first open a command console from the desktop menu. Make sure all is up to date by using the command:
pi@raspberrypi:~ $ sudo apt-get update
This will insure all appropriate packages currently installed are running the latest updates. If you are running a Debian distribution such as jessie you will need to edit the /etc/apt/sources.list file to add a backport to the latest version of R. Use the nano editor by using the command:
sudo nano /etc/apt/sources.list
This should produce the output as seen below:
pi@raspberrypi:~ $ sudo nano /etc/apt/sources.list ------------------------------------------------ GNU nano 2.2.6 File: /etc/apt/sources.list deb http://mirrordirector.raspbian.org/raspbian/ jessie main contrib non-free r$ # Uncomment line below then 'apt-get update' to enable 'apt-get source' deb-src http://archive.raspbian.org/raspbian/ jessie main contrib non-free rpi deb http://archive.raspbian.org/raspbian/ stretch main deb http://mirror.las.iastate.edu/CRAN/bin/linux/debian/ jessie main deb http://mirror.las.iastate.edu/CRAN/bin/linux/ubuntu xenial/
[ Read 8 lines ]
^G Get Help ^O WriteOut ^R Read File ^Y Prev Page ^K Cut Text ^C Cur Pos
^X Exit ^J Justify ^W Where Is ^V Next Page ^U UnCut Text^T To Spell
If you are using a Debian distribution you would add the line to the file
http://mirror.las.iastate.edu/CRAN/bin/linux/debian/ jessie main Replace the mirror portion with <URL of your favorite CRAN mirror>. Replace the 'jessie' portion with the name of the specific Debian distribution you are using. If you are using an Ubuntu distribution add a line with the appropriate changes for the specific Ubuntu distribution that you are using. Once these changes are made exit the nano editor using the ^O key command to write the file and then the ^X key command to return to the command line. You should now be able to issue the command: pi@raspberrypi:~ $ sudo apt-get install r-base r-base-core r-base-dev Once the download and install processes have completed you should now be able to invoke R from the command line or menu and see the latest version: pi@raspberrypi:~ $ R R version 3.3.2 RC (2016-10-23 r71578) -- "Sincere Pumpkin Patch" Copyright (C) 2016 The R Foundation for Statistical Computing Platform: arm-unknown-linux-gnueabihf (32-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. Natural language support but running in an English locale R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. > For other Linux distributions you would add a line similar to the above examples in the /etc/apt/sources.list. Check the documentation for your specific Linux platform for further information.
