Tag Archives: statistics
An R Tutorial: Visual Representation of Complex Multivariate Relationships Using the R qgraph Package, Part Two Repost
This is a repost of the original article that was posted as an embedded PDF file.
Douglas M. Wiig
April 8, 2018
Abstract
This article is part of my series of articles exploring the use of R
packages that allow for visualization of complex relationships among variables.
Other articles have examined visual representations produced by
the qgraph package in both large and small samples with more than three
variables. In this article I look specifically at the R qgraph package with a small
dataset of N=10, but a large number (14) of variables. Specifically, the R
qgraph.pca function is examined.
1 The Problem
In two previous blog posts I discussed some techniques for visualizing relationships
involving two or three variables and a large number of cases. In this
tutorial I will extend that discussion to show some techniques that can be used
on datasets with complex multivariate relationships involving three or more
variables.
In this post I will use a dataset called ‘Detroit.’ This data set was originally
used in the book ‘Subset selection in regression’ by Alan J. Miller published in
the Chapman and Hall series of monographs on Statistics and Applied Probability,
no. 40. It was also used in other research and appeared in appendix A
of ‘Regression analysis and its application: A data-oriented approach’ by Gunst
and Mason, Statistics textbooks and monographs no. 24, Marcel Dekker. Editor.
The Detroit dataset contains 14 variables and 10 cases. Each case represents
a year during the time period 1961-1973. The variables on which data was
collected are seen as possible predictors of homicide rate in Detroit during each
of the years studied.
These data are shown below
FTP UEMP MAN LIC GR CLEAR WM NMAN GOV HE WE HOM ACC ASR
260.35 11.0 455.5 178.15 215.98 93.4 558724. 538.1 133.9 2.98 117.18 8.60 9.17 306.18
269.80 7.0 480.2 156.41 180.48 88.5 538584. 547.6 137.6 3.09 134.02 8.90 40.27 315.16
272.04 5.2 506.1 198.02 209.57 94.4 519171. 562.8 143.6 3.23 141.68 8.52 45.31 277.53
272.96 4.3 535.8 222.10 231.67 92.0 500457. 591.0 150.3 3.33 147.98 8.89 49.51 234.07
272.51 3.5 576.0 301.92 297.65 91.0 482418. 626.1 164.3 3.46 159.85 13.0 55.05 30.84
261.34 3.2 601.7 391.22 367.62 87.4 465029. 659.8 179.5 3.60 157.19 14.57 53.90 17.99
268.89 4.1 577.3 665.56 616.54 88.3 448267. 686.2 187.5 3.73 155.29 21.36 50.62 86.11
295.99 3.9 596.9 1131.21 1029.75 86.1 432109. 699.6 195.4 2.91 131.75 28.03 51.47 91.59
319.87 3.6 613.5 837.60 786.23 79.0 416533. 729.9 210.3 4.25 178.74 31.49 49.16 20.39
341.43 7.1 569.3 794.90 713.77 73.9 401518. 757.8 223.8 4.47 178.30 37.39 45.80 23.03
The variables are as follows:
FTP – Full-time police per 100,000 population
UEMP – % unemployed in the population
MAN – number of manufacturing workers in thousands
LIC – Number of handgun licenses per 100,000 population
GR – Number of handgun registrations per 100,000 population
CLEAR – % homicides cleared by arrests
WM – Number of white males in the population
NMAN – Number of non-manufacturing workers in thousands
GOV – Number of government workers in thousands
HE – Average hourly earnings
WE – Average weekly earnings
HOM – Number of homicides per 100,000 of population
ACC – Death rate in accidents per 100,000 population
ASR – Number of assaults per 100,000 population
[J.C. Fisher ”Homicide in Detroit: The Role of Firearms”, Criminology, vol.14,
387-400 (1976)]
2 Analysis
As I have noted in previous tutorials, social science research projects often start
out with many potential independent predictor variables for a given dependent
variable. If these are all measured at the interval or ratio level, a correlation
matrix often serves as a starting point to begin analyzing relationships among
variables. In this particular case a researcher might be interested in looking at
factors that are related to total homicides. There are many R techniques to
enter data for analysis. In this case I entered the data into an Excel spreadsheet
and then loaded the file into the R environment. Install and load the following
packages:
Hmisc
stats
qgraph
readxl (only needed if importing data from Excel)
A correlation matrix can be generated using the cor function which is contained
in the stats package. To produce a matrix using all 14 variables use the
following code:
#the data file has been loaded as ’detroit’
#the file has 14 columns
#run a pearson correlation and #run a pearson correlation and put into the object ’detcor’
detcor=cor(as.matrix(detroit[c(1:14)]), method=”pearson”)
#
#round the correlation matrix to 2 decimal places for better viewing
round(detcor, 2)
#
#The resulting matrix will be displayed on the screen
Examination of the matrix shows a number of the predictors correlate with the
dependent variable ’HOM.’ There are also a large number of inter-correlations
among the predictor variables. This fact makes it difficult to make any generalizations
based on the correlation matrix only. As demonstrated in previous
tutorials, the qgraph function can be used to produce a visual representation of
the correlation matrix. Use the following code:
#basic graph with 14 vars zero order correlations
qgraph(detcor, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”spring”)
This will produce graph as seen below:
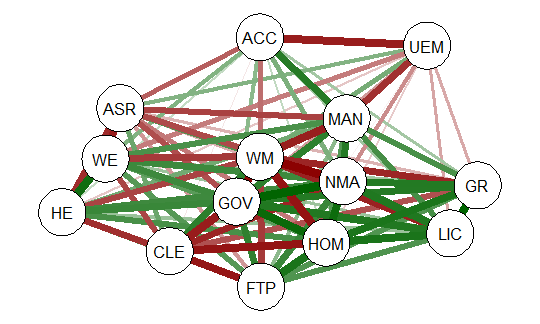
The graph displays positive correlations among variable as a green line, and
negative as a red line. The color intensity indicates the relative strength of the
correlation. While this approach provides an improvement over the raw matrix
it still rather difficult to interpret. There are many options other than those
used in the above example that allow qgraph to have a great deal of flexibility in
creating visual representation of complex relationships among variables. In the
next section I will examine one of these options that uses principal component
analysis of the data.
2.1 Using qgraph Principal Component Analysis
A discussion of the theory behind principal component exploratory analysis is
beyond the scope of this discussion. Suffice it to say that it allows for simplification
of a large number of inter-correlations by identifying factors or dimensions
that individual correlations relate to. This grouping of variables on specific factors
allows qgraph to create a visual representation of these relationships. An
excellent discussion of the theory of PCA along with R scripts can be found in
Principal Components Analysis (PCA), Steven M. Holland Department of Geology,
University of Georgia, Athens, GA, 2008.
To produce a graph using the ’detcor’ correlation matrix used above use the
following code:
#correlation matrix used is ’detcor’
#qgraph with loadings from principal components
#basic options used; many other options available
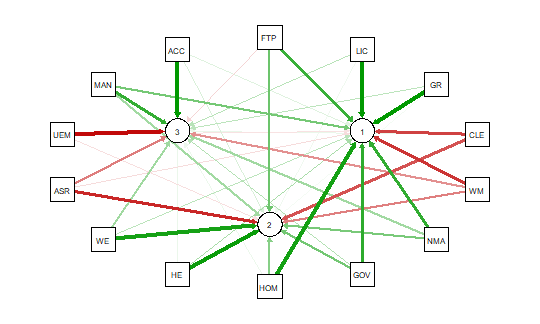
qgraph.pca(detcor, factor=3, rotation=”varimax”)
#this will yield 3 factors
This code produces the output shown below:
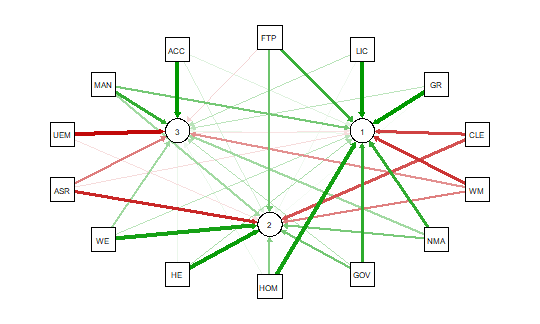
As noted above the red and green arrows indicate negative and positive loadings
on the factors, and the color intensity indicates the strength. The qgraph.pca
function produces a useful visual interpretation of the clustering of variables relative
to the three factors extracted. This would be very difficult if not impossible
with only the correlation matrix or the basic qgraph visual representation.
In a future tutorial I will explore more qgraph options that can be used to
explore the Detroit dataset as well as options for a larger datasets. In future
articles I will also explore other R packages that are also useful for analyzing
large numbers of complex variable interrelationships in very large, medium, and
small samples.
** When developing R code I strongly recommend using an IDE such as
RStudio. This is a powerful coding environment and is free for personal use as
well as being open source software. RStudio will run on a variety of platforms.
If you are developing code for future publication or sharing I would also recommend
TeXstudio, a LaTex based document development environment which is also free for personal use. This document was produced using TeXstudio 2.12.6
and RStudio 1.0.136.
An R Tutorial: Visual Representation of Complex Multivariate Relationships Using the R ‘qgraph’ Package, Part Two
An R programming tutorial by D.M. Wiig
This post is contained in a .pdf document. To access the document click on the green link shown below.
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, Part One
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, Part One
A Tutorial by D. M. Wiig, Professor of Political Science, Grand View University
In my most recent tutorials I have discussed the use of the tabplot() package to visualize multivariate mixed data types in large datasets. This type of table display is a handy way to identify possible relationships among variables, but is limited in terms of interpretation and the number of variables that can be meaningfully displayed.
Social science research projects often start out with many potential independent predictor variables for a given dependant variable. If these variables are all measured at the interval or ratio level a correlation matrix often serves as a starting point to begin analyzing relationships among variables.
In this tutorial I will use the R packages SemiPar, qgraph and Hmisc in addition to the basic packages loaded when R is started. The code is as follows:
###################################################
#data from package SemiPar; dataset milan.mort
#dataset has 3652 cases and 9 vars
##################################################
install.packages(“SemiPar”)
install.packages(“Hmisc”)
install.packages(“qgraph”)
library(SemiPar)
####################################################
One of the datasets contained in the SemiPar packages is milan.mort. This dataset contains nine variables and data from 3652 consecutive days for the city of Milan, Italy. The nine variables in the dataset are as follows:
rel.humid (relative humidity)
tot.mort (total number of deaths)
resp.mort (total number of respiratory deaths)
SO2 (measure of sulphur dioxide level in ambient air)
TSP (total suspended particles in ambient air)
day.num (number of days since 31st December, 1979)
day.of.week (1=Monday; 2=Tuesday; 3=Wednesday; 4=Thursday; 5=Friday; 6=Saturday; 7=Sunday
holiday (indicator of public holiday: 1=public holiday, 0=otherwise
mean.temp (mean daily temperature in degrees celsius)
To look at the structure of the dataset use the following
#########################################
library(SemiPar)
data(milan.mort)
str(milan.mort)
###############################################
Resulting in the output:
> str(milan.mort)
‘data.frame’: 3652 obs. of 9 variables:
$ day.num : int 1 2 3 4 5 6 7 8 9 10 …
$ day.of.week: int 2 3 4 5 6 7 1 2 3 4 …
$ holiday : int 1 0 0 0 0 0 0 0 0 0 …
$ mean.temp : num 5.6 4.1 4.6 2.9 2.2 0.7 -0.6 -0.5 0.2 1.7 …
$ rel.humid : num 30 26 29.7 32.7 71.3 80.7 82 82.7 79.3 69.3 …
$ tot.mort : num 45 32 37 33 36 45 46 38 29 39 …
$ resp.mort : int 2 5 0 1 1 6 2 4 1 4 …
$ SO2 : num 267 375 276 440 354 …
$ TSP : num 110 153 162 198 235 …
As is seen above, the dataset contains 9 variables all measured at the ratio level and 3652 cases.
In doing exploratory research a correlation matrix is often generated as a first attempt to look at inter-relationships among the variables in the dataset. In this particular case a researcher might be interested in looking at factors that are related to total mortality as well as respiratory mortality rates.
A correlation matrix can be generated using the cor function which is contained in the stats package. There are a variety of functions for various types of correlation analysis. The cor function provides a fast method to calculate Pearson’s r with a large dataset such as the one used in this example.
To generate a zero order Pearson’s correlation matrix use the following:
###############################################
#round the corr output to 2 decimal places
#put output into variable cormatround
#coerce data to matrix
#########################################
library(Hmisc)
cormatround round(cormatround, 2)
#################################################
The output is:
> cormatround > round(cormatround, 2) Day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 1.00 0.00 0.01 0.02 0.12 -0.28 0.22 -0.34 0.07 day.of.week 0.00 1.00 0.00 0.00 0.00 -0.05 0.03 -0.05 -0.05 holiday 0.01 0.00 1.00 -0.07 0.01 0.00 0.01 0.00 -0.01 mean.temp 0.02 0.00 -0.07 1.00 -0.25 -0.43 -0.26 -0.66 -0.44 rel.humid 0.12 0.00 0.01 -0.25 1.00 0.01 -0.03 0.15 0.17 tot.mort -0.28 -0.05 0.00 -0.43 0.01 1.00 0.47 0.44 0.25 resp.mort -0.22 -0.03 -0.01 -0.26 -0.03 0.47 1.00 0.32 0.15 SO2 -0.34 -0.05 0.00 -0.66 0.15 0.44 0.32 1.00 0.63 TSP 0.07 -0.05 -0.01 -0.44 0.17 0.25 0.15 0.63 1.00 |
|
|
The matrix can be examined to look at intercorrelations among the nine variables, but it is very difficult to detect patterns of correlations within the matrix. Also, when using the cor() function raw Pearson’s coefficients are reported, but significance levels are not.
A correlation matrix with significance can be generated by using the rcorr() function, also found in the Hmisc package. The code is:
#############################################
library(Hmisc)
rcorr(as.matrix(milan.mort, type=”pearson”))
###################################################
The output is:
> rcorr(as.matrix(milan.mort, type="pearson")) day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 1.00 0.00 0.01 0.02 0.12 -0.28 -0.22 -0.34 0.07 day.of.week 0.00 1.00 0.00 0.00 0.00 -0.05 -0.03 -0.05 -0.05 holiday 0.01 0.00 1.00 -0.07 0.01 0.00 -0.01 0.00 -0.01 mean.temp 0.02 0.00 -0.07 1.00 -0.25 -0.43 -0.26 -0.66 -0.44 rel.humid 0.12 0.00 0.01 -0.25 1.00 0.01 -0.03 0.15 0.17 tot.mort -0.28 -0.05 0.00 -0.43 0.01 1.00 0.47 0.44 0.25 resp.mort -0.22 -0.03 -0.01 -0.26 -0.03 0.47 1.00 0.32 0.15 SO2 -0.34 -0.05 0.00 -0.66 0.15 0.44 0.32 1.00 0.63 TSP 0.07 -0.05 -0.01 -0.44 0.17 0.25 0.15 0.63 1.00 n= 3652 P day.num day.of.week holiday mean.temp rel.humid tot.mort resp.mort SO2 TSP day.num 0.9771 0.5349 0.2220 0.0000 0.0000 0.0000 0.0000 day.of.week 0.9771 0.7632 0.8727 0.8670 0.0045 0.1175 0.0061 holiday 0.5349 0.7632 0.0000 0.4648 0.8506 0.6115 0.7793 0.4108 mean.temp 0.2220 0.8727 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 rel.humid 0.0000 0.8670 0.4648 0.0000 0.3661 0.1096 0.0000 0.0000 tot.mort 0.0000 0.0045 0.8506 0.0000 0.3661 0.0000 0.0000 0.0000 resp.mort 0.0000 0.1175 0.6115 0.0000 0.1096 0.0000 0.0000 0.0000 SO2 0.0000 0.0024 0.7793 0.0000 0.0000 0.0000 0.0000 0.0000 TSP 0.0000 0.0061 0.4108 0.0000 0.0000 0.0000 0.0000 0.0000 |
|
|
In a future tutorial I will discuss using significance levels and correlation strengths as methods of reducing complexity in very large correlation network structures.
The recently released package qgraph () provides a number of interesting functions that are useful in visualizing complex inter-relationships among a large number of variables. To quote from the CRAN documentation file qraph() “Can be used to visualize data networks as well as provides an interface for visualizing weighted graphical models.” (see CRAN documentation for ‘qgraph” version 1.4.2. See also http://sachaepskamp.com/qgraph).
The qgraph() function has a variety of options that can be used to produce specific types of graphical representations. In this first tutorial segment I will use the milan.mort dataset and the most basic qgraph functions to produce a visual graphic network of intercorrelations among the 9 variables in the dataset.
The code is as follows:
###################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
###################################################
cormat=cor(milan.mort) #correlation matrix generated
###################################################
###################################################
#now plot a graph of the correlation matrix
###################################################
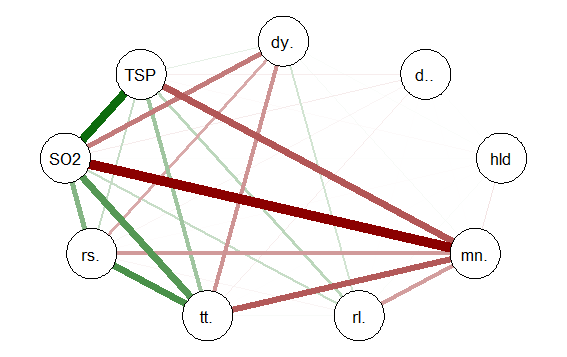
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”groups”, vsize=10)
###################################################
This code produces the following correlation network:
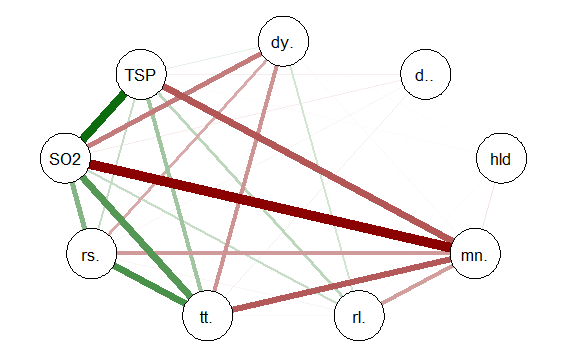
The correlation network provides a very useful visual picture of the intercorrelations as well as positive and negative correlations. The relative thickness and color density of the bands indicates strength of Pearson’s r and the color of each band indicates a positive or negative correlation – red for negative and green for positive.
By changing the “layout=” option from “groups” to “spring” a slightly different perspective can be seen. The code is:
########################################################
#Code to produce alternative correlation network:
#######################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
##############################################################
cormat=cor(milan.mort) #correlation matrix generated
##############################################################
###############################################################
#now plot a circle graph of the correlation matrix
##########################################################
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”spring”, vsize=10)
###############################################################
The graph produced is below:

Once again the intercorrelations, strength of r and positive and negative correlations can be easily identified. There are many more options, types of graph and procedures for analysis that can be accomplished with the qgraph() package. In future tutorials I will discuss some of these.
R for Beginners: Some Simple Code to Produce Informative Graphs, Part One
A Tutorial by D. M. Wiig
The R programming language has a multitude of packages that can be used to display various types of graph. For a new user looking to display data in a meaningful way graphing functions can look very intimidating. When using a statistics package such as SPSS, Stata, Minitab or even some of the R Gui’s such R Commander sophisticated graphs can be produced but with a limited range of options. When using the R command line to produce graphics output the user has virtually 100 percent control over every aspect of the graphics output.
For new R users there are some basic commands that can be used that are easy to understand and offer a large degree of control over customisation of the graphical output. In part one of this tutorial I will discuss some R scripts that can be used to show typical output from a basic correlation and regression analysis.
For the first example I will use one of the datasets from the R MASS dataset package. The dataset is ‘UScrime´ which contains data on certain factors and their relationship to violent crime. In the first example I will produce a simple scatter plot using the variables ‘GDP’ as the independent variable and ´crimerate´ the dependent variable which is represented by the letter ‘y’ in the dataset.
Before starting on this project install and load the R package ‘MASS.’ Other needed packages are loaded when R is started. The scatter plot is produced using the following code:
####################################################
### make sure that the MASS package is installed
###################################################
library(MASS) ## load MASS
attach(UScrime) ## use the UScrime dataset
## plot the two dimensional scatterplot and add appropriate #labels
#
plot(GDP, y,
main=”Basic Scatterplot of Crime Rate vs. GDP”,
xlab=”GDP”,
ylab=”Crime Rate”)
#
####################################################
The above code produces a two-dimensional plot of GDP vs. Crimerate. A regression line can be added to the graph produced by including the following code:
####################################################
## add a regression line to the scatter plot by using simple bivariate #linear model
## lm generates the coefficients for the regression model.extract
## col sets color; lwd sets line width; lty sets line type
#
abline(lm(y ~ GDP), col=”red”, lwd=2, lty=1)
#
####################################################
As is often the case in behavioral research we want to evaluate models that involve more than two variables. For multivariate models scatter plots can be generated using a 3 dimensional version of the R plot() function. For the above model we can add a third variable ‘Ineq’ from the dataset which is a measure the distribution of wealth in the population. Since we are now working with a multivariate linear model of the form ‘y = b1(x1) + b2(x2) + a’ we can use the R function scatterplot3d() to generate a 3 dimensional representation of the variables.
Once again we use the MASS package and the dataset ‘UScrime’ for the graph data. The code is seen below:
####################################################
## create a 3d graph using the variables y, GDP, and Ineq
####################################################
#
library(scatterplot3d) ##load scatterplot3d function
require(MASS)
attach(UScrime) ## use data from UScrime dataset
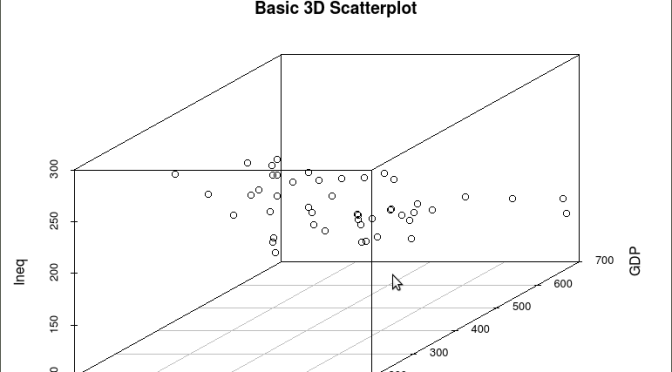
scatterplot3d(y,GDP, Ineq,
main=”Basic 3D Scatterplot”) ## graph 3 variables, y
#
###################################################
The following graph is produced:

The above code will generate a basic 3d plot using default values. We can add straight lines from the plane of the graph to each of the data points by setting the graph type option as ‘type=”h”, as seen in the code below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical lines from plane with this option
main=”3D Scatterplot with Vertical Lines”)
####################################################
This results in the graph:

There are numerous options that can be used to go beyond the basic 3d plot. Refer to CRAN documentation to see these. A final addition to the 3d plot as discussed here is the code needed to generate the regression plane of our linear regression model using the y (crimerate), GDP, and Ineq variables. This is accomplished using the plane3d() option that will draw a plane through the data points of the existing plot. The code to do this is shown below:
##############################################
require(MASS)
library(scatterplot3d)
attach(UScrime)
model <- scatterplot3d(GDP, Ineq, y,
type=”h”, ## add vertical line from plane to data points with this #option
main=”3D Scatterplot with Vertical Lines”)
## now calculate and add the linear regression data
model1 <- lm(y ~ GDP + Ineq) #
model$plane3d(model1) ## link the 3d scatterplot in ‘model’ to the ‘plane3d’ option with ‘model1’ regression information
#
####################################################
The resulting graph is:
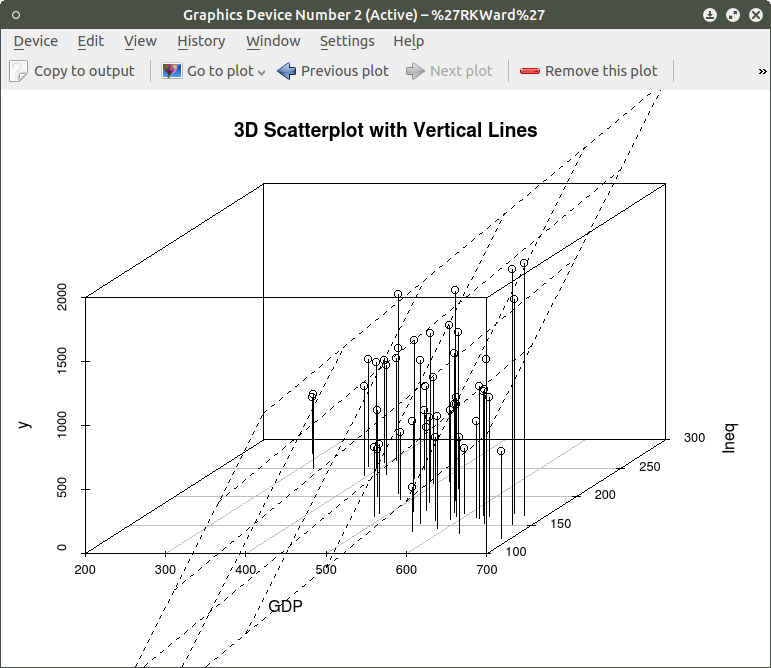
To draw a regression plane through the data points only change the ‘type’ option to ‘type=”p” to show the data points without vertical lines to the plane. There are also many other options that can be used. See the CRAN documentation to review them.
I have hopefully shown that relatively simple R code can be used to generate some informative and useful graphs. Once you start to become aware of how to use the multitude of options for these functions you can have virtually total control of the visual presentation of data. I will discuss some additional simple graphs in the next tutorial that I post.

R for Beginners: Using R Commander for Basic t Tests and One Way ANOVA
R for Beginners: Using R Commander for Basic t Tests and One Way ANOVA
A tutorial by D. M. Wiig
This post is contained in an embedded Word document. To read it full screen click on the icon in the lower right corner of the document window.
I hope that you found this tutorial informative. Stop back by to check for new installments. I have many currently in the writing stage.

R for Beginners: Using R Commander, Graphing and Correlation
A tutorial by Douglas M. Wiig
Please note that this post is an embedded Word document. To read the document full screen click on the icon in the lower right portion of the document window.
R for Beginners: Installing and Using the R Commander GUI, Part One
A tutorial by D.M. Wiig
This tutorial is posted as an embedded Word document. To view the document full screen click on the button in the lower right corner of the window. Please note that you must be online for the full page Word document display to work.

Ternary Diagrams Using R: The ggtern Package
Ternary Diagrams Using R: The ggtern Package
A tutorial by Douglas M. Wiig
There are a number of very useful and popular graphics packages available for R such as lattice, ggplot, ggplot2 and others. Some of these offer general purpose graphics capabilities and others are more specialized. A recently developed extension to the ggplot2 package is ggtern. This package is essentially a wrapper for a number of functions that can be used to create a variety of ternary diagrams. Ternary diagrams are useful when analyzing the relationship among three factors or elements. A ternary diagram essentially represents the proportions of three related factors in two-dimensional space.
Before running the script in this tutorial make sure that the packages ggplot, ggplot2, and ggtern are loaded into your R environment. A basic graph can be easily constructed. I will the use theoretical quantities Xa , Xb , and Xc to demonstrate a basic ternary diagram. In this simple example I will create a sample of n=5 by entering the data from the keyboard into a data frame ‘sampfile.’ To invoke the editor use the following code:
################################################### #create a sample file of n=5 ################################################### sampfile <-data.frame(Xa=numeric(0),Xb=numeric(0),Xc=numeric(0)) sampfile <-edit(sampfile) ###################################################
This will open up a data entry sheet with three columns labeled Xa, Xb, and Xc. The number that are entered do not matter for purposes of this illustration. The table I entered is as follows:
Xa Xb Xc
1 100 135 250
2 90 122 210
3 98 144 256
4 100 97 89
5 90 75 89
To produce a very basic ternary diagram with the above data set use the command:
################################################## #do basic graph with sample data ################################################## ggtern(data=sampfile,aes(x=Xa,y=Xb, z=Xc))+geom_point() ##################################################
This produces the graph seen below:
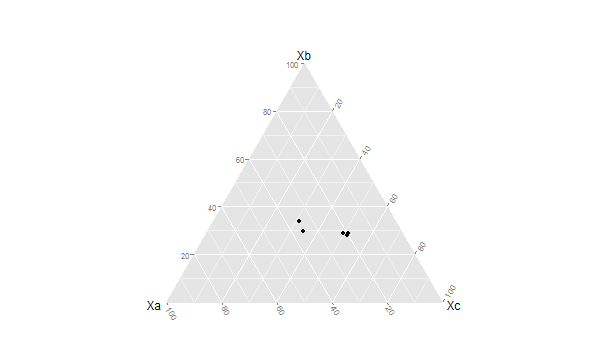
As can be seen the triangular representation of the dimensions Xa →Xb, Xc → Xa and Xb →Xc allow each case to be represented as a single point located relative to each of the three vectors. There are a large number of additions, modifications and tweaks that can be done to this basic pattern.
In the next tutorial I will discuss generating a more elaborate ternary diagram using election outcome data from British general elections. For more information about the ggtern package see the CRAN documentation and information as well as the web site http://www.ggtern.com for all of the latest news and developments.
Using R in Nonparametric Statistical Analysis, The Kruskal-Wallis Test Part Three: Post Hoc Pairwise Multiple Comparison Analysis of Ranked Means
Using the Kruskal-Wallis Test, Part Three: Post Hoc Pairwise Multiple Comparison Analysis of Ranked Means
A tutorial by Douglas M. Wiig
In previous tutorials I discussed an example of entering data into a data frame and performing a nonparametric Kruskal-Wallis test to determine if there were differences in the authoritarian scores of three different groups of educators. The test statistic indicated that at least one of the groups(group 1) was significantly different from the other two.
In order to explore the difference further it common practice to do post hoc analysis of the differences. There are a number of methods that have been devised to do these comparisons, but one of the most straightforward and easiest to understand is pairwise comparison of ranked means(or means if using standard ANOVA.)
Prior to entering the code for this section be sure that the following packages are installed and loaded:
PMCMR
prirmess
In part one data was entered into the R editor to create a data frame. Data frames can also be created directly using R script. The script to create the data frame for this example uses the following code:
#create data frame from script input
>Group <- c(1,1,1,1,1,2,2,2,2,2,3,3,3,3)
>authscore <-c(96,128,83,61,101,82,121,132,135,109,115,149,166,147)
>kruskal <- data.frame(Group, authscore)
The group identifiers are entered and assigned to the variable Group, and the authority scores are assigned to the variable authscore. Notice that each identifier is matched with an appropriate authscore just as they were when entered in columns using the data editor. The vectors are then assigned to the variable kruskal to create a data.frame. Once again the structure of the data frame can be checked using the command:
>str(kruskal)
resulting in:
'data.frame': 14 obs. of 2 variables: $ Group : num 1 1 1 1 1 2 2 2 2 2 ... $ authscore: num 96 128 83 61 101 82 121 132 135 109 ... |
|
|
|
It is often useful to do a visual examination of the ranked means prior to post hoc analysis. This can be easily accomplished using a boxplot to display the 3 groups that are presented in the example. If the data frame created in tutorial one is still in the global environment the boxplot can be generated with the following script:
>#boxplot using authscore and group variables from the data frame created in part one
>boxplot(authscore ~ group, data=kruskal, main=”Group Comparison”, ylab=”authscore”)
>
The resulting boxplot is seen below:

As can be seen in the plot, authority score differences are the greatest between group 1 and 3 with group 2 In between. Use the following code to run the Kruskal-Wallis test and examine if any of the means are significantly different:
#library(PMCMR)
with(kruskal, {
posthoc.kruskal.nemenyi.test(authscore, Group, “Tukey”)
}
The post hoc test used in this example is from the recently released PMCMR R package. For details of this and other post hoc tests contained in the package( see Thorsten Polert, Calculate Pairwise Multiple Comparisons of Mean Rank Sums, 2015. http://cran.r-project.org/web/packages/PMCMR/PMCMR.pdf.) The test employed here used the Tukey method to make pairwise comparisons of the mean rank authoritarianism scores of the three groups. The output from the script above is:
Pairwise comparisons using Tukey and Kramer (Nemenyi) test
with Tukey-Dist approximation for independent samples
data: authscore and Group
1 2
2 0.493 –
3 0.031 0.310
P value adjustment method: none
The output above confirms what would be expected from observing the boxplot. The only means that differ significantly are means 1 and 3 with a p = .031.
The PMCMR package will only work with R versions 3.0.x. If using an earlier version of R another package can be used to accomplish the post hoc comparisons. This package is the pgirmess package (see http://cran.r-project.org/web/packages/pgirmess/pgirmess.pdf for complete details). Using the vectors authscore and Group that were created earlier the script for multiple comparison using the pgirmess package is:
library(pgirmess)
authscore <- c(96,128,83,61,101,82,121,132,135,109,115,149,166,147)
Group <- c(1,1,1,1,1,2,2,2,2,2,3,3,3,3)
kruskalmc(authscore ~ Group, probs=.05, cont=NULL)
and the output from this script using a significance level of p = .05 is:
|
Multiple comparison test after Kruskal-Wallis p.value: 0.05 Comparisons obs.dif critical.dif difference 1-2 3.0 6.333875 FALSE 1-3 7.1 6.718089 TRUE 2-3 4.1 6.718089 FALSE |
|
|
As noted earlier the comparison between groups one and three is shown to be the only significant difference at the p=.05 level.
Both the PMCMR and the pgirmess packages are useful in producing post hoc comparisons with the Kruskal-Wallis test. It hoped that the series of tutorials discussing nonparametric alternatives common parametric statistical tests has helped demonstrate the utility of these approaches in statistical analysis.
In part four I will post the complete script used in all three tutorials.
