R for beginners: Some basic graphics code to produce informative graphs, part two, working with big data
A tutorial by D. M. Wiig
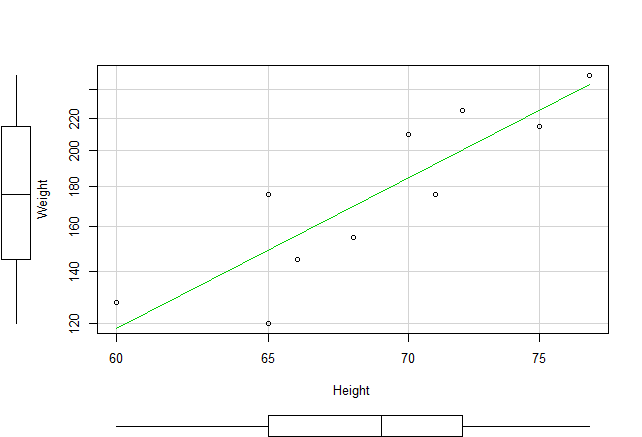
In part one of this tutorial I discussed the use of R code to produce 3d scatterplots. This is a useful way to produce visual results of multi- variate linear regression models. While visual displays using scatterplots is a useful tool when using most datasets it becomes much more of a challenge when analyzing big data. These types of databases can contain tens of thousands or even millions of cases and hundreds of variables.
Working with these types of data sets involves a number of challenges. If a researcher is interested in using visual presentations such as scatterplots this can be a daunting task. I will start by discussing how scatterplots can be used to provide meaningful visual representation of the relationship between two variables in a simple bivariate model.
To start I will construct a theoretical data set that consists of ten thousand x and y pairs of observations. One method that can be used to accomplish this is to use the R rnorm() function to generate a set of random integers with a specified mean and standard deviation. I will use this function to generate both the x and y variable.
Before starting this tutorial make sure that R is running and that the datasets, LSD, and stats packages have been installed. Use the following code to generate the x and y values such that the mean of x= 10 with a standard deviation of 7, and the mean of y=7 with a standard deviation of 3:
##############################################
## make sure package LSD is loaded
##
library(LSD)
x <- rnorm(50000, mean=10, sd=15) # # generates x values #stores results in variable x
y <- rnorm(50000, mean=7, sd=3) ## generates y values #stores results in variable y
####################################################
Now the scatterplot can be created using the code:
##############################################
## plot randomly generated x and y values
##
plot(x,y, main=”Scatterplot of 50,000 points”)
####################################################
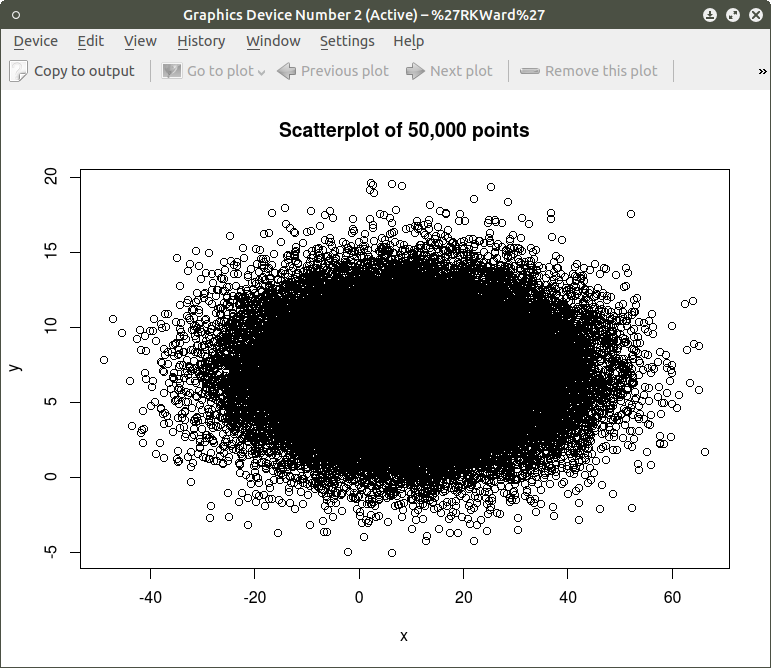
As can be seen the resulting plot is mostly a mass of black with relatively few individual x and y points shown other than the outliers. We can do a quick histogram on the x values and the y values to check the normality of the resulting distribution. This shown in the code below:
####################################################
## show histogram of x and y distribution
####################################################
hist(x) ## histogram for x mean=10; sd=15; n=50,000
##
hist(y) ## histogram for y mean=7; sd=3; n-50,000
####################################################
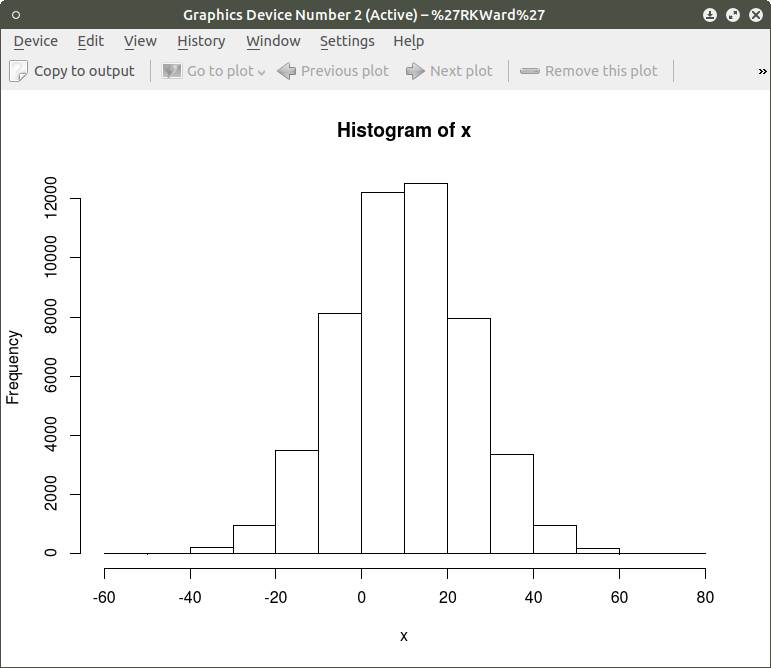
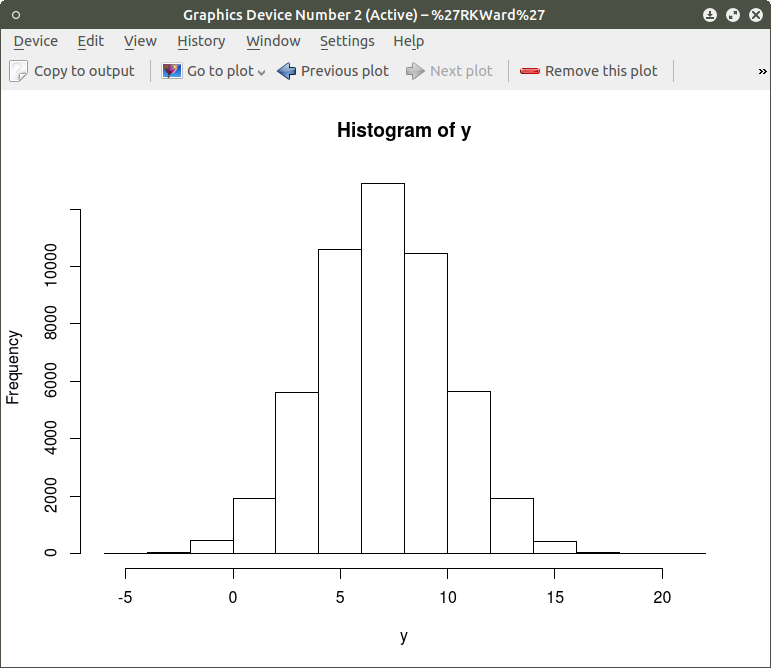
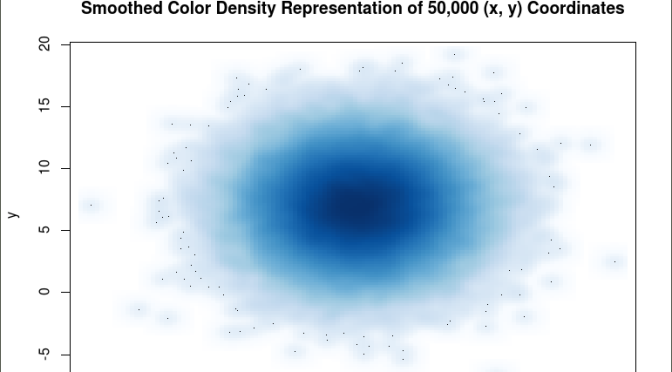
The histogram shows a normal distribution for both variables. As is expected, in the x vs. y scatterplot the center mass of points is located at the x = 10; y=7 coordinate of the graph as this coordinate contains the mean of each distribution. A more meaningful scatterplot of the dataset can be generated using a the R functions smoothScatter() and heatscatter(). The smoothScatter() function is located in the graphics package and the heatscatter() function is located in the LSD package.
The smoothScatter() function creates a smoothed color density representation of a scatterplot. This allows for a better visual representation of the density of individual values for the x and y pairs. To use the smoothScatter() function with the large dataset created above use the following code:
##############################################
## use smoothScatter function to visualize the scatterplot of #50,000 x ## and y values
## the x and y values should still be in the workspace as #created above with the rnorm() function
##
smoothScatter(x, y, main = “Smoothed Color Density Representation of 50,000 (x,y) Coordinates”)
##
####################################################

The resulting plot shows several bands of density surrounding the coordinates x=10, y=7 which are the means of the two distributions rather than an indistinguishable mass of dark points.
Similar results can be obtained using the heatscatter() function. This function produces a similar visual based on densities that are represented as color bands. As indicated above, the LSD package should be installed and loaded to access the heatscatter() function. The resulting code is:
##############################################
## produce a heatscatter plot of x and y
##
library(LSD)
heatscatter(x,y, main=”Heat Color Density Representation of 50,000 (x, y) Coordinates”) ## function heatscatter() with #n=50,000
####################################################
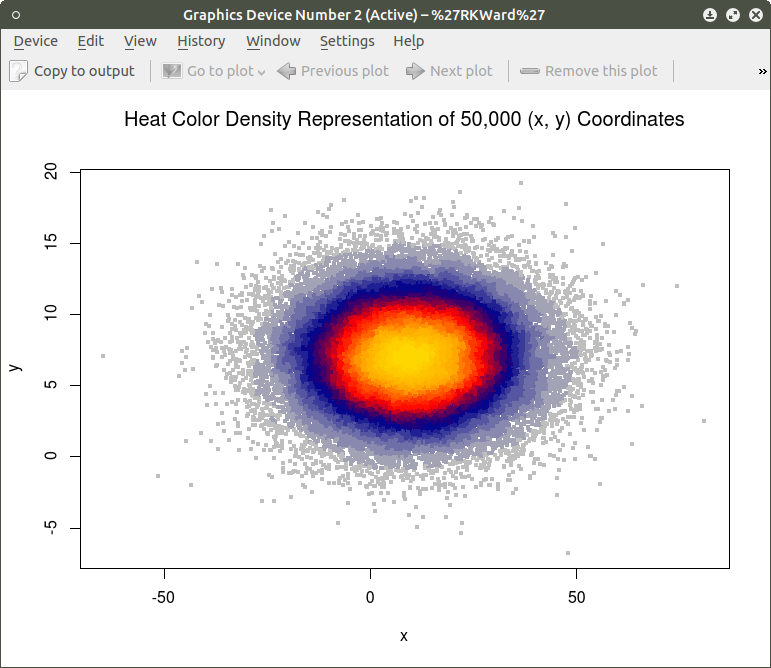
In comparing this plot with the smoothScatter() plot one can more clearly see the distinctive density bands surrounding the coordinates x=10, y=7. You may also notice depending on the computer you are using that there is a noticeably longer processing time required to produce the heatscatter() plot.
This tutorial has hopefully provided some useful information relative to visual displays of large data sets. In the next segment I will discuss how these techniques can be used on a live database containing millions of cases.